
毎年恒例の Data + AI Summit、いよいよ今年は 6月の San Francisco で開催されます(何回言うねん)
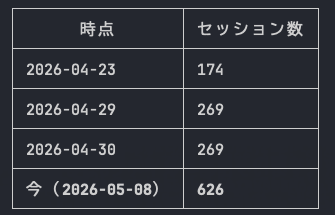
アジェンダを眺めていたら、なんと 2026年は269本!(2026/05/01時点) 様々なセッションが増えて、開催が近づくに従ってドンドン増えています!
とかいってたじゃないですか、今見たら626本になってるんです!w
というわけで、データエンジニアに引き続き、データサイエンティスト視点で、AI Agent / MLOps / LLMOps の中身を語ってくれる回だけを再度 20 本に選び直してみました!!!
このリストの想定読者は、
- LLM / Agent をプロダクションに乗せようとしているデータサイエンティスト
- MLflow / DSPy / Agent Bricks で eval や serving を本番運用している
- RAG / Vector Search / Memory の “production の壁” を越えたい
- Multi-Agent の observability や failure mode に頭を抱えている
- Deep Learning や Reinforcement Learning を真面目にやりたい
などの方々です!(もちろん見ていただきたいです!)
それでは早速、、、行きましょう!
I. 「Production AI を本気で!」枠(必見4本)
今年のテーマは何といっても 「production AI / LLM をどう動かすか」 です!PoC を超えて本番運用を考えている DS の皆さんにはこの4本を!
🔥 Mission-Critical Inference: Powering High-Scale AI in Production
- 登壇: Ankit Mathur, Tejas Sundaresan(Databricks)
- Lvl: Advanced
モデルを リリース したが、、、数百万 req/day を 適切なlatency / cost / zero downtime で捌く必要があるという productionの現実に向き合う1本!
- GPU autoscaling がどうトラフィックに追従するか
- request batching でコストをどこまで圧縮できるか
- 世界で最も負荷の高い推論ワークロードを支える Databricks Custom Model Serving の運用パターン
を、実装ベースで解説してくれます。production inference の プレイブック を持って帰りましょう!
🔥 Scaling Custom LLMs with vLLM and Databricks Model Serving
- 登壇: Colton Peltier, Mohamad Aboufoul(Databricks)
- Lvl: Advanced
provisioned throughput endpoint でデフォルトの LLM を使うのは簡単。でも、1000個の OSS / fine-tuned LLM を本気で動かしたい時にどうするか!?
- Serverless GPU Compute で deployment 設定の数時間を節約
- vLLM + GPU workloads のチューニングポイント
- 実装上のトレードオフ
OSS LLMをプロダクションで活かすには、、、これも中々表にでてこない内容です!
🔥 From Training to Production: MLOps for Deep Learning on Databricks
- 登壇: Michael Shtelma, Puneet Jain(Databricks)
- Lvl: Advanced
「Deep Learning は MLOps playbook を破壊する」── が、印象的な1本です!
- 数ギガバイト規模の重みデータ、GPU負荷の高い学習、分散チェックポイント、fine-tuning ループなど
- これらは classical ML の lifecycle pattern では収まらない
- 結果としてチームは脆いパイプラインをつぎはぎで組むハメになり、ダウンタイム・ドリフト・取り損ねた再学習サイクルで痛い目を見る
これに対し、Databricks上で end-to-end に DL MLOps を回す方法(distributed training + MLflow tracking、large model 用の model registry workflow、GPU-aware serving with traffic split)を見せてくれます。DL の MLOps を真剣にやる DS には必見!
🔥 Building Custom Models That Know Your Enterprise Knowledge with Reinforcement Learning
- 登壇: Jonathan Frankle(Chief AI Scientist @ Databricks)
- Lvl: Advanced
これは超アツい1本!
Databricks の Chief AI Scientist であるJonathan Frankle さん本人が、Databricks 内部の agent を OSS モデル + 強化学習(RL) でカスタマイズして動かしている話を解説してくれます!
- Databricks AI Runtime (AIR) での custom RL 実装
- 必要な “ingredients”(プロセス、データ、報酬設計)
- Databricks が独自に開発した novel な RL methods
RFT / Reinforcement Learning を本気で会社で展開したい方には、これは絶対に外せない1本です!
II. Agent Evaluation / Observability — 今年いちばんホットなトピックでは?(4本)
AI Agent が PoC を超えて production の段階に入ってきた今、evaluation と observability の体系化は最大の関心事だと思います。
🔥 Cascading Failures in Multi-Agent Systems
- 登壇: Oleksandra Bovkun(Databricks)
- Lvl: Advanced
Multi-Agent システムの評価は、もはや「単一モデル出力のテスト」じゃなくて、coordination layer の整合性検証だ、という視点転換から始まります。ありがちな failure mode として、
- poisoned shared memory(共有メモリの汚染)
- sub-optimal decision pattern(局所最適に陥る判断パターン)
- distributed hallucination(複数エージェント間の幻覚伝播)
を MLflow observability でどう拾うか、passive monitoring から active intervention へどう移行するか、が解説されます。Multi-Agent を本番で運用する DS は絶対に押さえたい!
Behind the Curtain: How We Do Eval in Genie / How We Built Agent Mode in Genie Spaces
- Lvl: 両方 Advanced
- 登壇: Genie Engineering Team(Databricks)
Databricks の Genie Engineering Team 自身が、Genie Spaceの eval 設計と Agent Mode の内部を語る回。
- 「Eval」セッションでは、offline benchmark / human-in-the-loop / production feedback loop の組み合わせと、それぞれのトレードオフ
- 「Agent Mode」セッションでは、planning / validation / context management の orchestration、multiple hypothesis を探索する実装
Databricks 自身がプロダクトとして真剣に向き合っている agent 設計、Genie Spaceを使ってる人もいると思いますが、これを中の人から聞ける貴重な機会です!
How to Implement Observability to Reduce Agent Sprawl
- 登壇: Alkis Polyzotis, Arthur Dooner(Databricks)
- Lvl: Advanced
「Agent Sprawl(エージェントの濫立)」という新しい architectural debt の話です。
- 複数チームがバラバラに agent を立てる → 全社の agent fleet を把握できなくなる
- どの agent がどの判断をしたか trace できない
- 一貫した policy も効かない
これを MLflow trace + Unity AI Gateway の policy enforcement で解決する、というアプローチが解説されます。Agent fleet 化はこれから必須と言う中、超実用的なセッションになると思います!
+ 推奨:The 52x Multiplier (Zepto), The Databricks Big Book of AgentOps
| タイトル | 着目点 |
|---|---|
| The 52x Multiplier: Zepto AI Agent Evaluation | MLflow 3.0 + DSPy で 80K 日次チケットの eval、52x ROI / CSAT +20.5% |
| The Databricks Big Book of AgentOps | “MLOps → AgentOps” の体系化、autonomous multi-step agent 用の CD/CI 再設計 |
III. RAG / Memory / Custom Model — 技術深堀り3本
📚 Effective document management and retrieval for generative AI(90分 Deep Dive)
production RAG を真面目に組む前に!
90分かけて RAG の全工程をカバー:
- document structuring の原則
- semantic vs. fixed-size chunking のトレードオフ
- contextual & multi-modal embedding
- retrieval optimization(re-ranking / contextual filtering / real-time quality evaluation)
Databricks 上の実装デモ込み。RAG の “本気のステップ” を 90分で詰め込めるぞ!
🧠 Why Vector Stores Are Not Enough: Using Lakebase as a Durable Memory Layer for Autonomous Agents
「Vector DB が AI Agent の memory」と言われがちですが、それは probabilistic similarity score (確率的な類似度スコア)にすぎない。エンタープライズ用途では “probably” じゃ困る、決定論的なトランザクションの状態が要る、というのが本セッションの主張。
- Two-Phase Commit Prompt:LLM に Lakebase の row を lock させてから外部 API を呼ばせ、hallucinated action を防ぐ
- Time Travel for Agents:Lakebase Branching で agent の “what-if” を作る
agentのmemoryアーキを真面目に考えている方に!Lakebaseをメモリレイヤにしましょう!
💊 Doubling Medical Safety: Fine-Tuning Open LLMs for Women’s Health Without Human Labels
医療 LLM の fine-tuning の壁として「safety rule を満たしたいが、real user data には触れない、expert labeling は高すぎる」というものがあります!
これに対し Flo Health は RFT-inspired synthetic fine-tuning を採用。Llama 3.3 70B を医療コンプラ準拠化して safety compliance を 2倍に。expert time を labeling ではなく LLM judge の設計に投資した、というのが本セッションの肝となると思います!
IV. Agent 設計の最前線(2本)
Beyond One-Shot AI: How to Design Context-Aware Agents
- Lvl: Advanced
「ほとんどの AI agent は one-shot:質問に答えて、忘れてしまう」── これに対し、数分〜数日かかる multi-step task をこなす agent を作るための設計パターンです。
- state を steps 横断で persist する方法
- failure からの graceful な recovery
- long-running workflow の orchestration
production agent を真面目に作りたい人の必須科目です!
Thinking Fast & Slow: How Databricks Built High-Speed and Deep Research Agents
- 登壇: Michael Bendersky(Director Research @ Databricks)
- Lvl: Advanced
agentic search に必要な 2モード:
- low-latency, low-cost mode:consumer-facing scale でレイテンシの許容範囲を満たす
- compute-intensive deep research mode:財務デューデリジェンス / 臨床評価 / 製造診断などの expert-level analysis
両者をどう設計し直したか、Databricks の Director Research 本人から聞ける回です!
V. MCP Security と Production パターン(3本)
🔐 MCP Security Deep Dive: How Databricks Secures Tool Access for Enterprise Users
- 登壇: Samrat Ray, Sunish Sohil Sheth(Databricks)
- Lvl: Advanced
agent が外部 tool に繋がる時代、security は 真っ先に解決すべき最優先課題です。1つのcredentialの漏洩、1つの監査証跡の欠落によって productionの信用が一夜で吹き飛ぶ、という重さ、、、。
- production での MCP integration の auth / authorization 実装
- tool への fine-grained access management
- 全 agent action の traceability 設計
MCP を本番で使うなら、これは絶対に聞いておきたいです!
⚡ Cache Smarter, Not Harder: Building a Semantic Cache Gateway with Lakebase and MLflow
- Lvl: Intermediate
LLM コストとレイテンシ削減の決定打になりそうな1本。
「exact string match の cache だと、ユーザーが同じ質問を別の言い方で聞いたら全部キャッシュヒットしない、、、」── これに対し semantic cache(意図に基づいた情報の検索)を Lakebase + MLflow で構築する方法です。production-ready な実装パターンが学べます!
🪙 Right Features, Right Time: Modernizing Real-Time Fraud Feature Serving on Databricks
- 登壇: Daniel Zhou(Coinbase)
- Lvl: Intermediate
Coinbase の Real-Time Mode + 宣言的 Feature APIs (features as code) + AI 支援 migration。この結果が以下です
- streaming infra コスト 90% 削減(p99)
- p99 freshness 95%+ 改善
self-built batch から Real-Time Mode へのパスを明確に語ってくれる、real-time ML feature serving の必読の事例です!
まとめ
DAIS 2026 を眺めていて改めて感じるのは、「AI Agent はもう PoC のフェーズを終わって、production の evaluation / observability / serving / governance / fine-tuning が本気で問われる年」 だということです!
ココまで色々紹介してきましたが、もう一回まとめると、
- Jonathan Frankle 本人による Reinforcement Learning カスタムモデル
- Mission-Critical Inference / vLLM / DL MLOps の3本立てで production AI を全部カバー
- Agent Sprawl という新しい概念
- Genie の中身を Engineering Team 自身が語る
- Real-Time Mode + Coinbase fraud features で 90% コスト削減の実例
- MCP Security が production で問われ始める
など、面白そうな内容が多いDAISになると思います!
それでは、6月の San Francisco で会えません〜が〜w
でもみんなでみましょうね〜w



コメントを残す