
毎年恒例の Data + AI Summit、いよいよ今年は 6月の San Francisco で開催されます。
アジェンダを眺めていたら、なんと 2026年は269本!(2026/05/01時点) 様々なセッションが増えて、開催が近づくに従ってドンドン増えています!
とかいってたじゃないですか、今見たら626本になってるんですよw
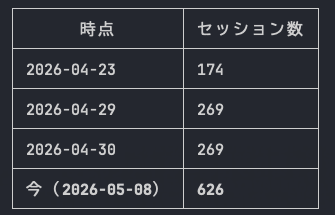
なので、セッション多過ぎぃ!!! の洪水に飲み込まれている皆さんのために再度269本626本のアジェンダから、データエンジニアのみなさんが興味がありそうなセッション 20 本を絞ってみました!
見ていただきたい方はこちら!(もちろんこれ以外の方にも見ていただきたい)
- Spark / Structured Streaming のチューニングを日常的にやっている
- Lakeflow Spark Declarative Pipelines を採用検討中、または導入済み
- Delta / Iceberg の互換戦略の動向を追いたい
- DABS や Asset Bundles で CI/CD をガリガリ回している
- ガチで OSS Spark を読み書きする派
などの方々です〜!
それでは早速、章ごとに見ていきましょう!再び!!!
I. 「OSS界の重鎮枠」が今年もすごい!必見4本
DAIS の楽しみのひとつが OSS Spark / Iceberg / Delta コミッタや創設者本人が話す回ですが(なんか書いた記憶がある)
🔥 Getting the Most Out of Spark Declarative Pipelines: Deep Dive on What’s New and Best
- 登壇: Michael Armbrust(Distinguished Software Engineer @ Databricks)
- Lvl: Advanced / 90分 Deep Dive
Spark 界の伝説 Armbrust さん本人による SDP の 90分 Deep Dive です。語ってくれるのは:
- execution model の中身とトレードオフ
- 信頼性とメンテナンス性を両立する proven design pattern
- batch と streaming の両モードでどう SDP を使い分けるか
- pipeline が複雑化したときの 典型的な落とし穴と回避法
90分という長尺なので、SDP 採用検討中の組織なら全員で見たいレベル。必見!めっちゃみたい!
🔥 Deep Dive Into Streaming and Batch ETLs With Lakeflow Spark Declarative Pipelines
- 登壇: Jacek Laskowski(”The Internals of Apache Spark” 著者)
- Lvl: Advanced
これも継続して必見の1本!
Spark 書籍のレジェンド著者 Laskowski さんによる、SDP の Internals 講座。本人の説明によると
- SDP の高レベル Python/SQL 抽象が Spark SQL と Structured Streaming のクエリにどう翻訳されるか
- 依存解決と DAG 構築のロジック
- 内部ステート管理、リトライ、インクリメンタル処理の仕組み
までソースを追える粒度で解説してくれるとのこと!これも聞きたい!SDP好き!
🔥 Format co-evolution: How Iceberg v4 and Delta 5.0 share a unified metadata
- 登壇: Ryan Blue(Iceberg開発者 / tabular共同創設者 / Databricks), Anoop Johnson(Principal Software Engineer / Databricks)
- Lvl: Intermediate
これも個人的に気になっている1本!
タイトルからワクテカしちゃいますが、Iceberg v4 の adaptive metadata tree を Delta Lake 5.0 が native content metadata として採用するという話、メチャクチャ気になりますねぇ。
- 両方のフォーマットクライアントが 同一の on-disk 構造を直接 read/write
- 翻訳レイヤなし、変換不要
- single-file commit でパフォーマンスも大幅向上
という、オープンテーブルフォーマット業界全体が激震する動向の発表です。Ryan Blue さん本人が話してくれる貴重な機会、これは絶対に聞きたい!
🔥 What’s New in Apache Spark™ 4.1?
- 登壇: Wenchen Fan, Daniel Tenedorio(両者 Spark Committer / Databricks)
- Lvl: Intermediate
Spark Committer 本人が話す 4.1 新機能網羅回。今年の目玉は:
- Spark Declarative Pipelines(SDP)の OSS 化
- Real-Time Mode の Structured Streaming 正式機能化(サブ秒レイテンシ)
- PySpark の Arrow-native UDF / UDTF
- Python Data Source filter pushdown
- Python worker logging の改善
Lakeflow SDP がいよいよ OSS Spark の機能になりますよー!
II. 「OSS Spark の中身ガチ深堀り」枠(3本)
Spark DSV2: Growing Up Fast — Szehon Ho, Anton Okolnychyi (Databricks)
DataSource V2 の最近の進化が一気に。procedure catalog + row identifier 対応で row-level operations が可能に、MERGE INTO の安全 schema evolution、partition filtering の強化、DML サマリの可視化、execution の重大な correctness fixなど、DEド真ん中!といった内容になると思います!
Read-Time CDF in Delta Lake — Gengliang Wang, Johan Lasperas (Databricks)
Delta の Change Data Feed は、これまで 書き込み時に変更を materialize するという、その場合ストレージコスト+レイテンシ増が発生していました。
新提案の Read-Time CDF は、Spark Data Source V2 の unified CDC interface と Delta の Row Tracking を使って、delta.enableChangeFeed を立てなくてもクエリ時に row-level changes を取得できるアーキテクチャにかわります。CDC をたくさん使っている組織のコスト構造が変わる可能性アリ!
Streaming at Scale With Real-Time Mode: Sub-Second Train Telemetry Across the Netherlands
オランダ国鉄 NS の 1日 1000億ポイント超のテレメトリを sub-second で処理する事例。PySpark + SQL のみで構築、UDF や追加コンポーネントなしという潔さがポイント。会場では生のテレメトリの live demo もある予定で、Real-Time Mode の生のユースケースがみれるかも?
III. SQL / パフォーマンス / モデリング深堀り(3本)
🆕 Advanced SQL Patterns for Production Analytics — Serge Rielau, Fabien Contaminard (Databricks)
これは Spark/Databricks の SQL の中の人 Serge Rielau さん登壇です!
production で使うべき SQL パターン集として、
- temporary tables / stored procedures / multi-statement transactions を本番で安全に使う
- 効率的な document extraction pipeline
MATCH_RECOGNIZEで sales funnel 解析を効率化- 複雑なロジックを Unity Catalog の 再利用可能 / governed asset に変換
を実演する予定です。SQL をガッツリ運用してるDEの方やアナリストの方 にはぴったりな1本になりますね!
🆕 Diagnosing Performance Bottlenecks in Databricks Lakehouse — Shannon Barrow (Databricks)
これも実用度の高い1本!Databricks の Principal SA Shannon Barrow による パフォーマンス診断 framework。
- query / data layout / concurrency / system-level どの層に bottleneck があるかの切り分け方
- execution plan と runtime signal の読み方
- 表面的なチューニングで見落とす本当の根本原因の探し方
を、Databricks エンジンの実行モデルに基づいて解説。現場で使える repeatable な diagnostic アプローチを持ち帰れます、AIを活用したアプローチもあるぞ!
Modern Data Modeling at Scale: Advanced Patterns — Shannon Barrow, Kyle Hale (Databricks)
「データモデリングの 10 のミス」を題材に、Databricks Lakehouse でできる PK / FK、identity columns で surrogate key、column-level data quality constraints などを Bronze / Silver / Gold に渡って実装する具体パターン。Medallion の中で、本気のデータモデリングをどう実装するかがわかります!
IV. Unity Catalog の “Open” 化が今年のテーマ(3本)
How to scale governance to External Engines with Unity Catalog Open APIs — Dipankar Kushari, Alex Jiang (Databricks)
UC を 多様なエンジン・クラウド・チームから使うための Open API の運用パターン。Delta Lake / Apache Iceberg を含む open table format への secure interoperable access、automated identity-based credentials によるアクセス管理、単一ポリシーフレームワークなど。
🆕 Interoperability With Unity Catalog: Beyond Databricks — Liran Bareket (Databricks)
20分の Lightning Talk ですが、衝撃の構想です!
Lakehouse Federation で UC を “catalog of catalogs” 化して、
- Snowflake
- BigQuery
- OneLake
- AWS Glue
- Postgres
を UC ひとつで統一管理、さらに Genie で横断クエリも可能!
Row-level security も全ソース横断で uniform に効くという話で、これが実用化されたら enterprise の データ戦略が180度変わっちゃうかも?シンプルにネタとしても面白そうですw
🆕 Unity Catalog: Advanced Field-Proven Patterns from the Experts — Pamela Pettit, Jyotsna Bharadwaj (Databricks)
Databricks の SA 2人による UC ガバナンスのフィールド検証パターン。
- governance at scale で centralized vs domain-driven のバランスをどう取るか
- catalog organization の structured guardrail
- metadata curation を加速して、true な data discovery と self-service を実現
UC の運用に頭を抱えている事ってやっぱりあると思います、そんな時にみてください!明日から使える話です!
V. 大規模本番事例(4本)
How Supercell Uses Databricks (MAU 3億)
Clash of Clans / Brawl Stars MAU 3億を支える基盤、Auto Loader でのイベント取り込み、データ民主化、ML での player harm 検出までフルスタック。Head of Data Platform 本人が登壇するので、プラットフォーム責任者目線の話が聞けるのも良いポイント!
Beyond Medallion: Architecting Disney’s DATOS for Complex Real-Time Data Streams
Disney が Lakehouse 上に構築した DATOS(contextual aggregation and abstraction layer)。Structured Streaming + Lakeflow SDP で Kafka / Kinesis / Data Lake の多源吸収、上流のスキーマ揺らぎや配信遅延も吸収する設計に?
Medallion の “次” を考えている人は要チェック!
🆕 Cielo: 6,000+ pipelines migrated EMR → Databricks
LATAM 決済大手 Cielo の超大規模マイグレーション事例!
- 6,500 pipelines を全て査定
- 3,000 legacy jobs を廃止
- AWS EMR + Oracle Exadata + 分散ガバナンスの “fragmented landscape” から、Delta Lake + Serverless + UC ベースの unified Lakehouse へ統合
6,500パイプラインてw
「うちにも legacy が山のようにあるけど、移行を進められるんだろうか…」と悩んでる組織には、めちゃくちゃ参考になる事例!
From Cost Mystery to Cost Mastery: COPA Airlines
利益率がカミソリのように薄い航空業界で、世界第3位の operating margin と業界トップクラスの定時運航率を維持しながら、データコストの指数関数的増加を防いだ話。「legacy data silos → high-velocity lakehouse」への移行の “global masterclass” として語られる予定!
VI. その他、押さえておきたい3本
DABS: do like a pro — Hubert Dudek
Asset Bundles の ドキュメントには載っていない実戦パターンとショートカット集を、ライブデモで!20分なのでちょっとした隙間で見れるかも?
🆕 Stateful Apps for Thousands of Users — Andre Furlan Bueno (Databricks)
Databricks Apps を stateful にスケールさせる方法。horizontal scaling + session affinity + sharding の under-the-hood をしっかり解説してくれる、実装側 DE / アーキ向けの濃い1本。
いい感じのデータアプリケーション作っちゃいましょ!
Inside our Lakeflow Journey at SEGA Europe
日次 数十億件のゲーム telemetry を扱う SEGA Europe の Lakeflow SDP 移行記。Football Manager 2026 ローンチで本番検証済み、”fragile manual jobs → self-healing lakehouse” のリアルな wins / lessons / unexpected challenges。
まとめ
DAIS 2026 のアジェンダを見ていて改めて感じるのは、今年は本当にデータプラットフォームの中身が動く転換点が多い年だということです!
ご紹介した中でも、
- Spark 共同創業者 Michael Armbrust 本人による SDP 90分 Deep Dive
- Iceberg 共同創設者 Ryan Blue 本人による Delta 5.0 + Iceberg v4 のメタデータ統合解説
- Lakehouse Federation で UC を catalog of catalogs にするという構想
- Cielo の 6,000+ pipelines 大規模マイグレーション事例
などなど面白そうな内容が多いなとおもいます!
それでは、6月の San Francisco で会いましょう〜!ぼくはいかないけど日本でみますけど〜wいきたいですけど〜w



コメントを残す