
データ基盤の選定や比較記事を読む中で、「Databricksはデータサイエンティストやエンジニア向けのプラットフォームで、ビジネスユーザーには難しい」という声をいただくことがあります。
データ基盤の比較検討をしている方、あるいは過去にDatabricksを候補に入れたものの「うちには難しそうだ」と見送った経験がある方にこそ、ぜひ読んでいただきたい内容です。
確かに、少し前まではそうした側面がありました。しかし、今のDatabricksは大きく変わっています。本記事では、よくいただくイメージと現在の姿のギャップを率直にお伝えします!
Databricksの思想・概要・特徴
Databricksは「データとAIの民主化」を掲げるプラットフォームです。過去の経緯より「Apache Sparkベースのデータ処理基盤」として語られることも多いのですが、現在のDatabricksはSparkだけのプラットフォームではありません。Data Lakehouse、リアルタイムストリーミング、MLOps、生成AIアプリケーション開発、BI、データガバナンスまでを ひとつのプラットフォーム上で 提供する統合基盤へと進化しています。
Databricksの根底にある思想は以下の3つだと考えています。
- オープンであること ― Delta Lake、Iceberg、MLflow、Unity Catalogなど、コア技術をオープンソースとして公開。ベンダーロックインを避け、お客様のデータ主権を守ります!
- データとAIの統合 ― データエンジニアリングからBI分析、機械学習、生成AIまで、データのライフサイクル全体をひとつのプラットフォームでカバーします!
- 誰もがデータを活用できること ― ノーコードのUI、自然言語でのデータ操作、AIアシスタントなど、技術レベルを問わずデータにアクセスできる環境を提供します!
機能・特性の比較についてよく言われること
お客様やパートナー様との会話の中で、Databricksについて以下のようなイメージをお持ちの方にお会いすることがあります。
| 項目 | Databricks |
|---|---|
| 想定ユーザー | データサイエンティスト / エンジニア |
| UI | コード中心(Python, Spark) |
| データ統合 | Data Lakehouse |
| 分析/AI開発 | 自由度高い(基本コード) |
| ガバナンス・再現性 | 手動構築 |
| 学習コスト | 高 |
| 導入スピード | 中〜長期 |
素直に言って、これは少し前のDatabricksの姿です。現在は大きく変わっています。
| 項目 | Databricks |
|---|---|
| 想定ユーザー | ビジネスユーザー / アナリスト / データサイエンティスト / データエンジニア ― すべてのデータ活用層 |
| UI | ノーコード(AI/BI Dashboard, Genie、Lakeflow Designer(現在プライベートプレビュー)など)からフルコード(Notebook)まで、ユーザーのスキルに応じた複数のインターフェースを提供 |
| データ統合 | Data Lakehouse ― 構造化・非構造化データを統一的に管理 |
| 分析/AI開発 | AI/BI Dashboardによるノーコード分析、Genieによる自然言語でのデータ対話、Notebook/MLflowによる高度なML/AI開発まで幅広く対応可能 |
| ガバナンス・再現性 | Unity Catalogによる統合ガバナンス ― アクセス制御、データリネージ、品質管理を自動的に一元管理。手動構築は不要 |
| 学習コスト | ビジネスユーザーはGenieやDashboardから即日利用可能。Genie CodeやAI/BI Genieが学習・開発をAIでサポート。段階的なスキルアップパスを提供 |
| 導入スピード | Genie CodeやAI Dev Kitによる開発生産性の向上、Databricks Apps・テンプレート活用による短期立ち上げが可能 |
以下、特に変化が大きいポイントを詳しくご紹介します。
1. ノーコード・ローコードの充実
「Databricks = コードを書ける人だけのプラットフォーム」というイメージは過去のもの!
- AI/BI Dashboard:ドラッグ&ドロップでダッシュボードを作成できます。SQLの知識がなくても、ビジネスユーザーが自ら分析・可視化を行えます
- Genie:自然言語でデータに質問できるAIアシスタントです。「先月の売上トップ10の商品は?」と聞くだけで、適切なクエリが実行され、結果が返ってきます。ビジネスユーザーが自分の言葉でデータと対話できる世界を実現しています
- ノーコードパイプライン:Declarative Pipelines(旧Delta Live Tables)により、GUIベースでデータパイプラインを構築できます。さらにLakeflow Designer(現在プライベートプレビュー中)がGAすると、GUIでのETLがより充実します
- Agent Bricks:プロンプトのみで、AIエージェントを構築できるサービスであるAgent Bricksもあります。マルチにエージェントが動くコードを書くと難しいAIエージェントでも簡単に作成することができます
2. AIが学習コストを劇的に下げる
「Databricksは学習コストが高い」と言われてきた背景には、Python/Spark/SQLといったコーディングスキルが前提だったことがあります。今のDatabricksは、AIの力で「使う人の壁を下げる」 アプローチを取っています。
- Genie Code:Notebook上で動作するAIアシスタントです。「このデータフレームをグラフにして」「このエラーを直して」といった自然言語の指示でコードが生成されるため、Pythonに不慣れなアナリストでもNotebookを活用できるようになります
- AI/BI Genie:自然言語でデータに質問するだけで分析結果が得られます。SQLを書く必要すらありません。ビジネスユーザーにとっての「学習コスト」はほぼゼロ!
つまり、「スキルを身につけてからDatabricksを使う」のではなく、「Databricksを使いながらAIにサポートされてスキルが身につく」 という体験に変わっています。学習コストが障壁になる時代は終わりつつあります。
3. Unity Catalogによるガバナンスの自動化
「ガバナンスは自分で作り込む必要がある」と思われがちですが、Unity Catalog の登場により状況は一変しています!
- 統合アクセス制御:テーブル、ファイル、MLモデル、ダッシュボードなど、すべてのデータ資産に対するアクセス権をひとつの仕組みで管理
- 自動リネージ追跡:データがどこから来て、どう加工され、どこで使われているかを自動的に記録・可視化
- データ品質モニタリング:Lakehouse Monitoringにより、データの品質異常を自動検知
- AI Governanceの実現:MLモデルやAIエージェントの管理・監査もUnity Catalogで一元的に対応
ガバナンスのために別途ツールを導入したり、手動で仕組みを構築する必要はなくなっているわけです!
4. AIが導入スピードを加速する
「導入に時間がかかる」というイメージの背景には、パイプライン構築やアプリケーション開発をすべて手書きのコードで行う必要があった、という事情がありました。前述のAIツールは、学習コストだけでなく 「作る人の工数を減らす」 ことで導入スピードにも直結します。
- Genie Codeによる開発生産性の向上:Notebook上で「S3のCSVを読み込んでDelta Tableに変換するパイプラインを作って」と指示すれば、コードのひな形が即座に生成されます。ETLパイプラインやデータ変換処理のコードを一から書く必要がなく、生成→微調整→実行というサイクルで開発スピードが大幅に上がります
- AI Dev Kit(Claude Code等)によるローカル開発の効率化:Claude Codeなど外部のAIエージェントからDatabricks環境に接続し、AIにコードを書かせながら開発できるツールキットです。Databricksのワークスペースにログインしなくても、普段使い慣れたツールから開発を進められるため、既存のエンジニアがすぐに生産的になれます
- Databricks Apps:開発したアプリケーションをDatabricks上でそのままホスティング・公開できます。別途インフラを用意する必要がなく、プロトタイプから本番運用への移行がスムーズです
- テンプレートとサンプル:業種・ユースケース別のソリューションテンプレート(ソリューションアクセラレータ)が充実しており、ゼロからの設計が不要なケースも増えています
「専門人材を揃えてから着手する」のではなく、「今いるメンバーでAIの力を借りながら素早く立ち上げる」 というアプローチが現実的になっています。
5. 全社展開への対応
「活用できる人が限定的で、全社展開に時間がかかる」というご懸念もよく伺います。
現在のDatabricksは、ペルソナごとに最適なインターフェースを用意する ことで、この課題に正面から取り組んでいます。
最近はNotebookではなくSQLだけでDatabricksを使っている、という方も非常に増えています!
| ペルソナ | 使うもの | 学習コスト |
|---|---|---|
| ビジネスユーザー | Genie、AI/BI Dashboard、Agent Bricks(AIエージェントをノーコードで構築・利用できるサービス) | 低 ― 即日利用可能 |
| データアナリスト | SQL Editor、Dashboard、Notebook | 低〜中 |
| データエンジニア | Notebook、Lakeflow Spark Declarative Pipelines、Databricks Asset Bundles | 中 |
| データサイエンティスト | Notebook、MLflow、Databricks AI | 中〜高 |
| MLエンジニア | MLflow、Model Serving、Agent Framework | 高 |
重要なのは、すべてのペルソナが同じデータ基盤の上で働く ということです。ビジネスユーザーがGenieで分析したデータも、データサイエンティストがモデル学習に使うデータも、同じUnity Catalogで管理された同じデータです。ツールごとにデータがサイロ化する心配がありません。
コスト・ROI視点
「Databricksは専門人材の確保コストが大きく、成果が出るまでに時間がかかる」という声も耳にします。ここでは、少し違った角度からコストとROIについてお話しします。
プラットフォーム統合によるTCO削減
データ基盤を複数の製品の組み合わせで構成する場合、それぞれのライセンスコストに加えて、ツール間の連携設定・運用・バージョン管理といった「見えないコスト」が発生します。
Databricksは ひとつのプラットフォーム でDWH・ETL・ML・AI・BI・ガバナンスをカバーするため、
- ライセンスコストの一本化
- ツール間連携の運用コスト削減
- データコピーの削減(同一基盤上で処理するため、ツール間のデータ移動が不要)
といった TCO(総保有コスト)の観点で有利 になるケースが多くあります。
オープンフォーマットによるコスト最適化
DatabricksはDelta Lakeや、Icebergというオープンフォーマットでデータを保持します。データは お客様自身のクラウドストレージ(S3、ADLS、GCS) に保存されます。
- データの保管コストはクラウドストレージの料金のみ
- Databricksを離れても、データはそのまま他のツールからアクセス可能
- ベンダーロックインのリスクを最小化
コンピュートのコストパフォーマンス
データ基盤のランニングコストにおいて大きな割合を占めるのがコンピュート費用です。ここでDatabricksが強みを持つのは、処理性能の高さがそのままコスト削減につながる という点です。
- Photonエンジン:Databricks独自の次世代実行エンジンであるPhotonは、従来のSparkに比べて数倍の高速化を実現します。同じクエリがより短時間で完了するため、コンピュートの稼働時間が短くなり、結果としてコストが下がります
- Serverless Compute:サーバーレスモデルにより、クエリの実行時のみリソースが割り当てられます。アイドル時間のコストが発生せず、起動も高速です。従来のようにクラスタを常時起動しておく必要がありません
- Predictive Optimization:テーブルのメンテナンス処理をDatabricksが自動で最適なタイミングで実行します。手動チューニングの運用工数が不要になるだけでなく、常にデータが最適化された状態が維持されるため、クエリ実行コストも低減します
つまり、単価の比較だけでなく「同じ処理をどれだけ短時間・低コストで完了できるか」というコストパフォーマンスの視点 で見ると、Databricksは非常に競争力があります。処理が速く終わればコンピュート課金も少なくなります、これはシンプルですが見落とされがちなポイントです。
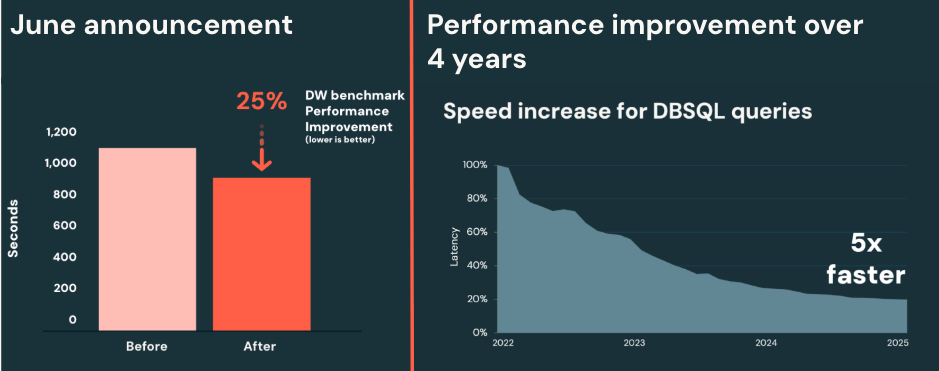
これは前回のDAISで発表された資料ですが、何もしなくてもDatabricksの基盤は5倍早くなっているわけです。
短期のROIも十分実現可能
「成果が出るまで1年以上」というのは、すべてをゼロからコードで構築していた時代の話です。現在は以下のような短期成果パターンがあります。
- Genie + 既存データ:既にDWHやデータレイクにあるデータをUnity Catalogに登録し、Genieで自然言語検索を可能にし、これによって 数日から数週間で全社的なデータ活用の入口を提供
- AI/BI Dashboard:既存のSQLクエリをベースに、ノーコードでダッシュボードを構築し、数日で可視化環境を提供
- Lakeflow Spark Declarative Pipelines:既存のETL処理をGUIベースのパイプラインに移行して 運用コストの削減
- Genie CodeやAI Dev Kit:AIにコードを書かせることで、自身でコードを書く工数を最小限にしながら短期で開発を進めることが可能に
選択基準
データ基盤の選定において、「自社の人材構成と文化に合っているか」で選ぶことは非常に重要です。その上で、判断材料として以下のポイントを考慮いただければと思います。
Databricksが力を発揮するケース
- データとAIを一体的に活用したい ― 分析だけでなく、MLモデルの開発・運用、生成AIアプリケーションの構築まで見据えている
- スケーラビリティが重要 ― データ量の急激な増加やリアルタイム処理の要件がある
- ベンダーロックインを避けたい ― オープンフォーマット・オープンソース技術でデータ主権を確保したい
- マルチクラウド戦略がある ― AWS、Azure、GCPのいずれでも同じプラットフォームを利用可能
- 将来的な拡張性を重視する ― 今はBI中心でも、将来的にML/AIへの拡張を見込んでいる
「Databricksは難しい」と感じたことがある方へ
もし過去にDatabricksを検討して「うちには難しい」と感じた経験がある方は、ぜひ 今のDatabricks をもう一度見ていただきたいと思います。GenieやAI/BI Dashboardの登場、そして各種AIとの連携により、ビジネスユーザーが直接データを活用できる環境は飛躍的に改善されています。
また、Databricksはパートナーエコシステムも充実しており、導入支援・研修・運用サポートを提供するパートナー企業も多数存在いたします!
自社だけですべてを構築する必要はありません!
まとめ
Databricksに対して「エンジニア向け」「難しい」「導入に時間がかかる」というイメージをお持ちの方は、まだ少なくないかもしれません。少し前まではそうした側面があったことは事実です。
しかし、今のDatabricksは 「エンジニアだけのプラットフォーム」から「すべてのデータ活用者のためのプラットフォーム」 へと大きく進化しています。
| よくあるイメージ | 今のDatabricks |
|---|---|
| コードが書けないと使えない | Genie・AI/BI Dashboard、Genie Code、各種AI開発ツールでノーコード活用可能 |
| ガバナンスは自分で構築 | Unity Catalogで自動的に統合管理 |
| 導入に時間がかかる | Genie Code・AI Dev Kit(Claude Code)でコードを生成し、少人数でも素早く立ち上げ可能 |
| エンジニア専用 | ビジネスユーザーからMLエンジニアまで全層対応 |
データ基盤の選定は、最新の情報をもとに判断いただくことが大切です。過去のイメージではなく、今の姿 を見ていただいた上で、自社に最適な選択をしていただければと!
データとAIの活用を本気で進めたい企業にとって、Databricksは強力な選択肢であると確信しています!是非ご相談ください!




コメントを残す