
おはようタイ!

朝起きてTiDBさんともっと仲良くなりたいと思ったんだ。
ということで今日はTiDBさんのデータをDatabricksへリアルタイムに取り込むためにどうするか、、、やっていこうと思います!
まず構成を考える
今回の構成はこの様になります。なるはずです。
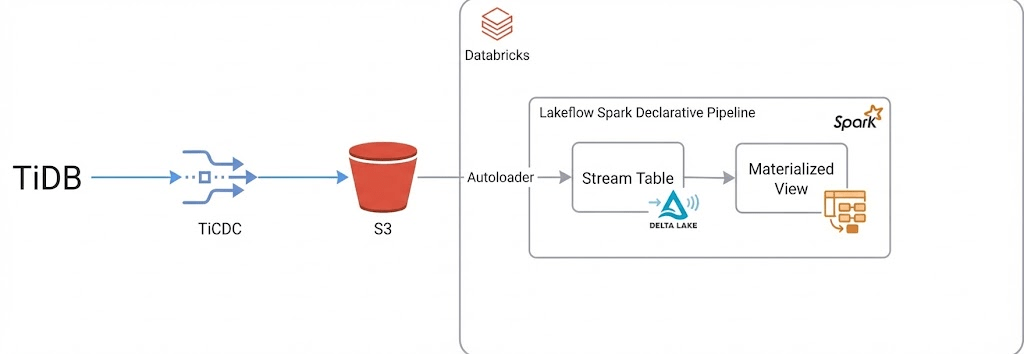
TiDBからのデータを受けるためのTiCDCでデータをS3にリアルタイムに連携し、それをAutoloderで受けてDatabricksへ連携します。
DatabricksではLakeflow Spark Declarative Pipeline(長いので以下SDP)を使ってStream Table、そしてMaterialized Viewで後段のワークフローに連携していく準備を整えていきます。
TiCDCとは
詳しくはここを見ていただければと思いますが、名前の通りTiDBで発生したデータをChange Data Captureで他のシステムと連携するためのサービスです。MySQLや、PostgreSQLで言えばレプリケーションと言われているようなことがTiDBでも実現できる事になります。
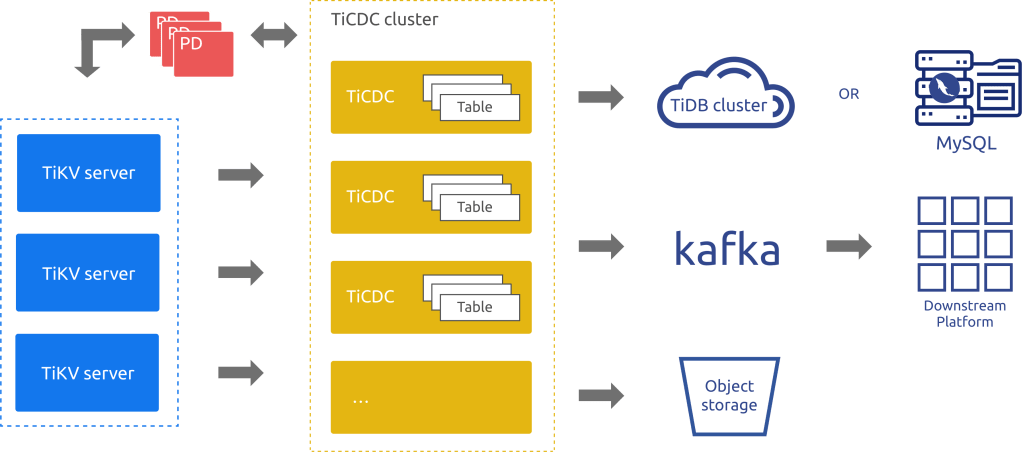
図を抜粋しますが、簡単に言うとTiKVサーバ群から発生したデータ変更のログがTiCDCサーバ群に送られ、TiCDCはそれをS3や、Kafka、別のTiDBへと連携することができる、というサービスです。
今回はS3への連携で考えてみますが、より低いレイテンシで処理したいならKafkaなどの選択肢もあると思います。
TiCDCのデータ形式
S3を前提として考えた時にもちろんファイル出力を行うことになるんですが、ファイルタイプとしてはAVRO、CSVなどが使用可能です。
今回は一番シンプルなCSVを選択したいと思います。
そして、ここでごめんなさいをするのですが、TiDBのTiCDCは無料プラン内で有効化できないので、データ構造を合わせたファイルを作ってS3に配置していきますw
データ構造としてはゲームのデータが入っていると仮定して、この様な形とします。
CREATE TABLE `gamedb`.`game_users` (
`user_id` BIGINT NOT NULL COMMENT 'ユーザーID',
`player_level` INT NOT NULL COMMENT 'プレイヤーレベル',
`username` VARCHAR(100) NOT NULL COMMENT 'ユーザー名',
`status` TINYINT NOT NULL COMMENT 'ステータス',
`coins` INT NOT NULL DEFAULT 0 COMMENT 'コイン数',
`experience` INT NOT NULL DEFAULT 0 COMMENT '経験値',
`rank_points` INT NOT NULL DEFAULT 0 COMMENT 'ランクポイント',
`created_at` DATETIME NOT NULL COMMENT '作成日時',
`last_active_date` DATE NOT NULL COMMENT '最終アクティブ日',
`character_class` VARCHAR(50) NOT NULL COMMENT 'キャラクタークラス',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
実際に作ったCSVはこんな感じです。
"I","game_users","gamedb","462942445345455152","10001","PaladinTiger3623","2","500","1126","96","2025-11-24 21:54:08","2025-01-11","Archer"
"U","game_users","gamedb","462486856366191373","10001","RogueRider3341","98","85322","69899","142","2025-12-19 21:54:08","2025-05-31","Archer"
"U","game_users","gamedb","463238649819684540","10001","DragonMaster3453","74","88346","32146","390","2025-12-17 21:54:08","2025-02-01","Mage"
"I","game_users","gamedb","463128456596929628","10002","IceMaster7261","4","2909","1288","56","2025-11-19 21:54:08","2025-11-21","Mage"
"U","game_users","gamedb","462610701387385168","10002","WizardMaster5820","58","39968","49505","128","2025-12-15 21:54:08","2025-05-05","Archer"
"D","game_users","gamedb","462519264253957487","10002","StarRunner5721","89","67543","7949","960","2025-11-29 21:54:08","2025-10-16","Archer"
各カラムの意味はこちらで見ていただければと思いますが、簡単に書くと
- 1カラム目が操作(Insert,Update,Delete)を表しています
- 2カラム目は、スキーマ
- 3カラム目が、テーブル名
- 4カラム目はオプションですが、commit-tsと言われる操作時間を入れることができますので入れています
commit-tsはオプションですが後ほどSCD Type 2などを行う際に重要になりますので出力しています。commit-tsの仕様はこちらにあります
commit-tsは最初46bitがフィジカルタイムスタンプ、後半18bitがロジカルタイムスタンプとなります。
こんな感じ。
0000011000101000111000010001011110111000110111000000000000000100 ← This is 443852055297916932 in binary
0000011000101000111000010001011110111000110111 ← 最初の46Bitは物理時間を表す
000000000000000100 ← 後半の18Bitは論理時間を表す
このファイル群をS3においたら準備完了です!
S3にDatabricksからアクセスできるように外部ロケーションの設定をしておきましょう!(仮に s3://<bucket名>/ticdc_demo/ とする)
Lakeflow Spark Declarative Pipeline(以下SDP)の構築 – Autoloaderとデータの取得
次はDatabricks側で作業を開始しましょう!
Databricks上で「ジョブとパイプライン」から、「ETLパイプライン」を作成!
ファイルを追加していきます。
まずは
次にファイルを追加していきます。[game_user_cdc_raw.sql] です。
-- =============================================================================
-- ソーステーブル(Bronze層)
-- =============================================================================
CREATE OR REFRESH STREAMING TABLE game_users_cdc_raw_sql AS
SELECT
_c0 AS operation,
_c1 AS table_name,
_c2 AS database,
CAST(_c3 AS BIGINT) AS commit_ts,
CAST(_c4 AS INT) AS user_id,
_c5 AS username,
CAST(_c6 AS INT) AS level,
CAST(_c7 AS INT) AS experience,
CAST(_c8 AS INT) AS coins,
CAST(_c9 AS INT) AS gems,
CAST(_c10 AS TIMESTAMP) AS last_login,
CAST(_c11 AS DATE) AS created_at,
_c12 AS player_class,
_rescued_data
FROM STREAM(read_files(
's3://<bucket名>/ticdc_demo/',
format => 'csv',
header => false,
rescuedDataColumn => '_rescued_data',
schemaEvolutionMode => 'rescue'
));
これだけで、Autoloaderして、S3から増分データを取得してエグザクトリーワンスとして扱えるストリーミングテーブルが作成されます。このテーブルはもちろんUnity Catalogからも見えます。
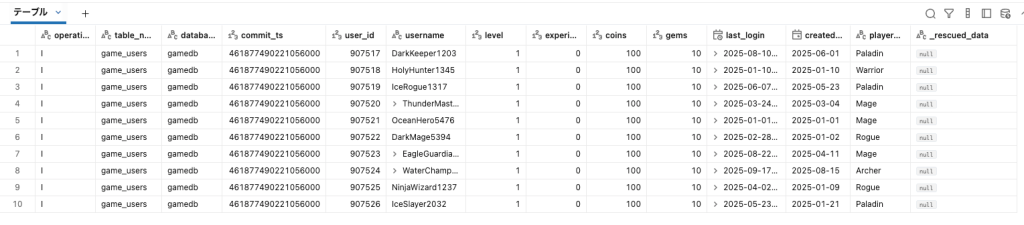
CDCと、SCD(Snowly Changing Dimension) TYPE 2の有効化
次はこのストリーミングテーブルもとにしてCDCでデータを受けるテーブルを作成します!
[game_users.sql] を追加します
このブロックは2つのSQLに分かれています。
-- =============================================================================
-- ターゲットテーブル(Silver層)
-- =============================================================================
CREATE OR REFRESH STREAMING TABLE game_users
COMMENT 'Game users table with CDC applied (readable as normal table)';
実際にデータが保存されるターゲットのテーブルです。こちらはシンプルにテーブルが作られているだけになります。カラムは自動推論されるので何も指定していません。
-- =============================================================================
-- AUTO CDC - CDC適用
-- =============================================================================
CREATE FLOW game_users_cdc_flow AS AUTO CDC INTO game_users
FROM STREAM(game_users_cdc_raw)
KEYS (user_id)
APPLY AS DELETE WHEN operation = 'D'
SEQUENCE BY commit_ts
COLUMNS * EXCEPT (operation, commit_ts)
STORED AS SCD TYPE 2;
CDCの設定部分になる、FLOWの定義です。
これには、AUTO CDC INTOというSQL構文を使って実現します。
以下はAUTO CDC INTOの主要な設定です。
- APPLY AS DELETE WHEN: この値になっている行は削除として動く
- SEQUENCE BY: この列で順序を決定(同一キー内での適用順序)
- KEYS: 主にプライマリキーを設定。レコードがターゲットテーブルに存在するか確認し、存在しない場合はINSERT、存在する場合UPDATE
- APPLY AS DELETE WHEN: DELETE操作の識別条件
非常にシンプルにCDCが実現できるのがわかるかと思います。
加えてここでSCD Type 2の設定もここで行っています。SCD Type 2とはテーブルの変更履歴を保存する手法です。
各カラムにStartDateとEndDateを含めて保存していくことでどの様に各データが更新されたかをヒストリカルに取っておく事が可能となります。
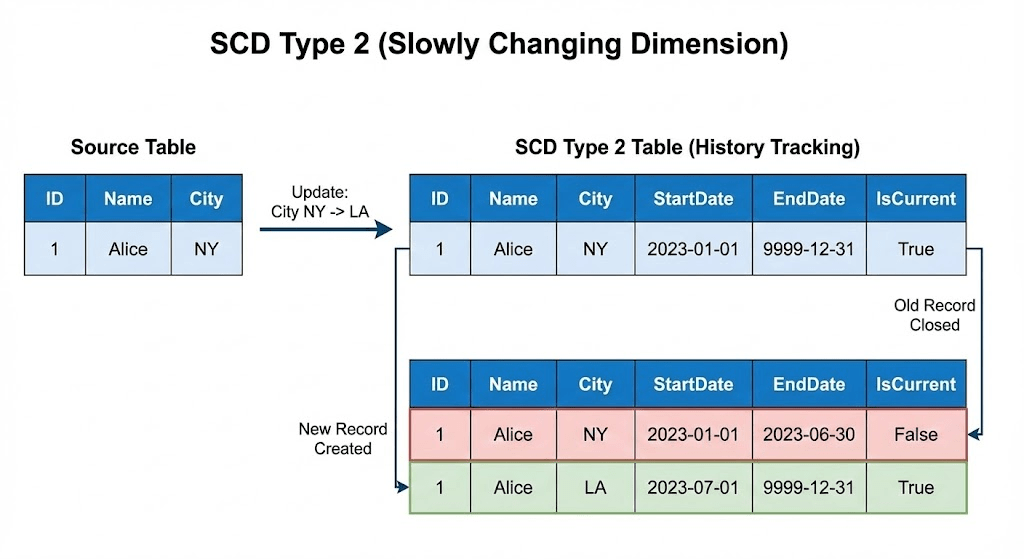
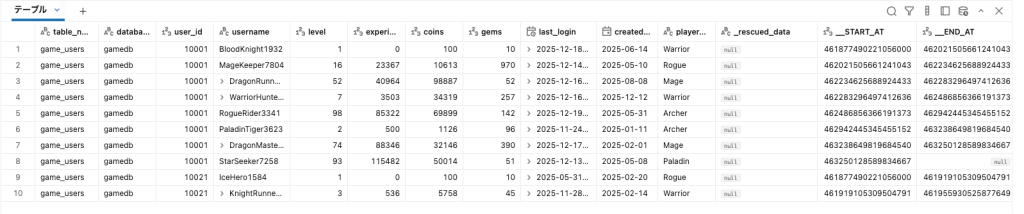
SDPはデフォルトでこのSCD Type 2に対応しており、上のSQLの中で”STORED AS SCD TYPE 2“で指定するだけで、__START_ATにそのPRIMARY_KEYのROWデータが保存された時間が、__END_ATにそのROWデータが削除された時間が入ります(まだ消されていない=最新データならNULLになります)
SCD Type 2を実際実装しようとするとちょっと面倒くさいですが、SDPなら設定一つで簡単に使えるようになるわけです!
実際のデータはこうなります。
最後にこれを集計して表示するマテリアライズド・ビューを追加します、ファイル名は [game_users_current.sql] とします。
-- =============================================================================
-- マテリアライズドビュー: 現在のデータのみ(最新スナップショット)
-- =============================================================================
CREATE OR REFRESH MATERIALIZED VIEW game_users_current
CLUSTER BY (user_id)
COMMENT 'Current snapshot - active records only'
AS
SELECT
user_id,
username,
level,
experience,
coins,
gems,
last_login,
created_at,
player_class
FROM game_users
WHERE __END_AT IS NULL;
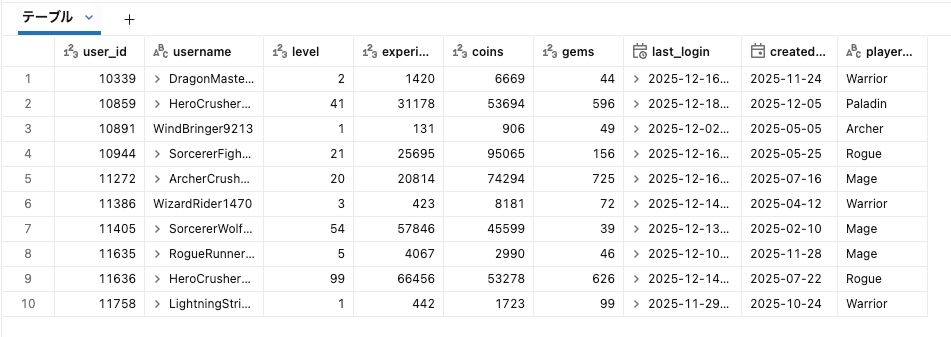
最新データは__END_ATがNULLのもの、といいました。
なので最新データだけみたいのであれば__END_ATがNULLという条件で持ってくればOKです。
データはこうなります。
SCD Type 2には既存の履歴もすべて取られているので、過去のある時点、例えば12月時点のスナップショットのマテリアライズドビューなども作成可能です!
CREATE OR REFRESH MATERIALIZED VIEW game_users_snapshot_20251201
COMMENT '2025年12月1日00:00:00 UTC時点のスナップショット'
AS
WITH target_config AS (
SELECT (UNIX_TIMESTAMP(TIMESTAMP'2025-12-01 00:00:00.000') * 1000) << 18 AS ts
)
SELECT
u.user_id,
u.username,
u.level,
u.experience,
u.coins,
u.gems,
u.last_login,
u.created_at,
u.player_class
FROM game_users u
WHERE u.__START_AT < (SELECT ts FROM target_config)
AND (u.__END_AT IS NULL OR u.__END_AT >= (SELECT ts FROM target_config));
めっちゃ便利にリアルタイムにデータアクセスできるようになります!
ということで、TiDBのCDCデータをDatabricksで取り込んでSDPで使えるようにしてみました!
今回やったことをまとめるとこんな感じになります。
- TiCDCからS3へのデータ出力(今回は模擬データでしたが汗
- AutoloaderでS3からストリーミング取り込み
- AUTO CDC INTOで簡単にCDCの設定
- SCD Type 2で履歴管理も楽チン
- マテリアライズドビューで最新データも過去のスナップショットも設定可能
特にSDPのAUTO CDC機能はかなり使いがいのある機能かなーと思っております。INSERT/UPDATE/DELETEの判定とか、順序制御とか、履歴管理とかそれが設定だけで実現できるのは正直ラクです。
しかもSCD Type 2まで簡単に使えるってのがめちゃくちゃ良くて、データの変遷を追えるのは多分運用にも聞いてくると思います「あれ、このユーザーっていつレベル上がったんだっけ?」とか「このユーザ不正ユーザじゃないの?」みたいなチェックに使えるわけです。
ぜひみなさんも試してみてください、今回はTiCDCでしたが、他のプロダクトでもCDCできると嬉しいユースケースはたくさんあると思います!
ではー!楽しいデータエンジニアリングライフをどうぞ!





コメントを残す