
タイトルがシンプルイズベスト!
ということで、DatabricksはDeltaが最初に対応したOpen Table Formatではありますが、今ではIcebergもマネージドテーブルとして対応してます!
それをザックリ紹介していきましょう!
Delta使ってもいいのよw
まずIcebergを始めるには
まずはシンプルにIcebergテーブルを作ってみましょう!
Unity Catalogが有効になっているワークスペースであれば、めちゃくちゃ簡単です。 SQLで書くとこんな感じ!
CREATE OR REPLACE TABLE kuwano_catalog.iceberg_demo.sample_table (
id BIGINT,
name STRING
)
USING iceberg
TBLPROPERTIES ('format-version' = 3);
はい、できた!USING ICEBERGって書くだけです!今ならIceberg v3がいいですよね、ということでテーブルプロパティで指定すればIceberg v3が使えます!(ベータです)
Icebergテーブルが作成されてます、はい簡単!
データの追加も普通、
INSERT INTO kuwano_catalog.iceberg_demo.sample_table (id, name) VALUES
(1, 'Alice'),
(2, 'Bob'),
(3, 'Charlie');
はい、普通ですw
Deltaと同じ感覚で使えますし、なんなら普通のデータベースみたいに使えますよね(そらそうだけど
Unity Catalogがいい感じに管理してくれてるわけです!
IcebergとUnity Catalog
ということでIcebergとUnity Catalogの話へ、、、。
DatabricksのIcebergテーブルって、Unity Catalogのマネージドテーブルとして統合されていて、ここは結構地味だけど効いてくる感じの所かと思います
つまり、
- 権限管理がUnity Catalogで一元管理できる
- Databricks使うならコレができんとあかん
- データリネージも取れる
- V3でカラムリネージも取れるようになりました
- Delta Sharingで共有可能
- これもできんとあかんし、便利
要するにDeltaでもIcebergでも、Unity Catalogで統一的に管理できるわけですね、何回も言いますけど地味ですw
地味なんですが結構使用感は良いはずで、ココが大事!
メタデータの管理もUnity Catalogがやってくれるので、Iceberg Catalogの構築とか考える必要ないわけです。楽ちんや!w
ヒストリーも見れるし、、、。
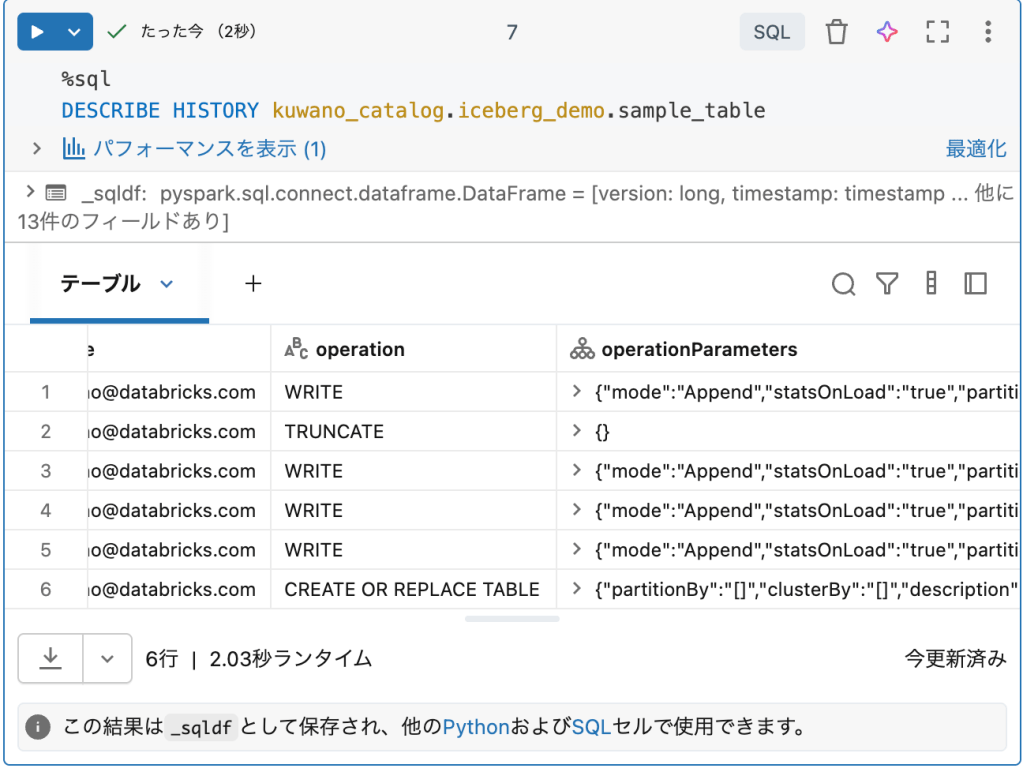
メタデータのカタログも勝手にできてるわけです。
リネージも、、、例えばこんな感じでDeltaテーブル作って、、、。
CREATE TABLE kuwano_catalog.iceberg_demo.sample_table_delta
AS
SELECT * FROM kuwano_catalog.iceberg_demo.sample_table;
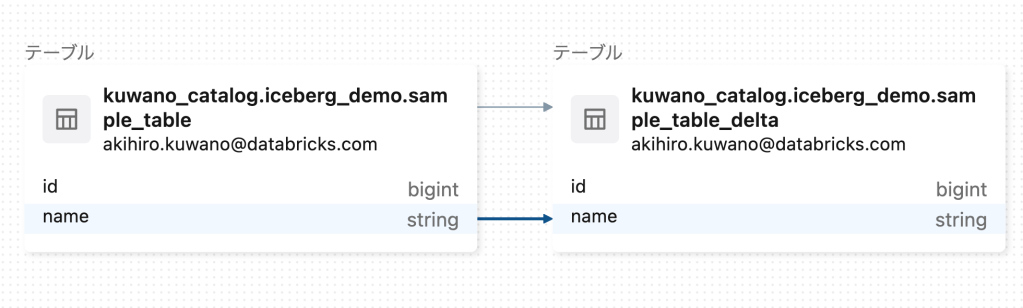
こうじゃよ、DeltaとIcebergでももちろんリネージは勝手に取られおるのじゃ。楽じゃねえ。
ほかのサービスのを読みたい
Databricks内が楽なのはわかった。じゃあ他のサービスで作ったIcebergテーブルをDatabricksで読みたい場合はどうするの?って話もまあでますよね。
これも簡単か、、、というとまず外部システムによっちゃうのでね、、、単純に言いづらい所もありますが、
例えばSnowflakeで作ったIcebergテーブルとか、Trino/Prestoで作ったIcebergテーブルとか、そういうのを読めるわけです。
これで、他のサービスで作ったIcebergテーブルもDatabricksから読めるようになりました!マルチクラウド、マルチエンジン時代の到来ですね!(これは訓練ではない
ほかのサービスから読みたい
では次は、、、DatabricksでIcebergテーブル作ったけど、それを他のサービスから読みたい場合!
これもIcebergの良いところで、Icebergのメタデータさえ読めれば他のエンジンからも読めます!
例えばSnowflakeだとこんな感じ(とーちかさんが前記事書いてくれたのでこっちを見てね再び)
SELECT * FROM iceberg.schema.my_iceberg_table;
相互にSQLを打つだけで済むわけですね!ありがたや。
もちろんSnowflakeからは読めますし、Trinoや、Sparkなど他のディストリビューションからも読めます。
オープンフォーマットの強みはここにあるわけで、ベンダーロックインを避けたい!とか、相互運用を前提にしたいって場合にIcebergを選ぶのは一つの選択肢だと思います!
今の制限
さて、ここで現実的な話をしておきましょう。
DatabricksのIceberg対応、めちゃくちゃ便利なんですけど、まだいくつか制限があります。
詳しくはまずはドキュメントをみていただければと思いますが、相互運用という意味では難しい部分があります、例えばDatabricksでも、Snowflake、AWS、Google Cloud、各社でのIceberg対応には差分が大きいです。多分Databricksは頑張って対応している方だと思っていますが、V3を対応している中でV4が出てきたりとかなりイタチごっこな部分もあり、なかなか難しい部分もあります。
Icebergを信用しすぎるのもちょっと違うと思っており、Icebergは銀の弾丸ではないと思っています。なので考え方としては、使うプロダクトでは事前にIcebergの何ができて何ができないかを確認する事が大事だと思っています。
外部テーブルとして使う手もありますが、その場合もマネージドテーブルの恩恵が受けられなくなるので、注意が必要です。
とはいえ、基本的な使い方なら全然問題ないレベルですので上手く相互運用していきましょう!
それを踏まえたうえでの今の使い分け
じゃあ結局、DeltaとIceberg、どっち使えばいいの?って話ですよね。
僕が思う使い分けはこんな感じです!
Deltaを使うべき場合:
- Databricks内で完結するワークロード
- パフォーマンスが大事
- Change Data Feed(CDF)やリキッドクラスタリングなどの現状Deltaでしか使えない機能を使いたい
Databricksならとりあえず迷ったらDeltaで良いと思いますw
Icebergを使うべき場合:
- マルチエンジン、マルチクラウドでのデータ共有が必要
- Hidden PartitionなどのIceberg独自機能が使いたい
要するに、Databricksに置いてで言えば「ポータビリティ重視ならIceberg」「安定運用、パフォーマンス重視ならDelta」という感じでしょうか、、、?
とはいえ、多分Databricksで使う場合においては併用になると思っていて、以下のように考えるのが基本になると思います。
- ブロンズ、シルバーはDelta
- ゴールドは必要に応じてIceberg、もしくはUniform
- 各種使いたい機能がある場合はそれを選択する
- 他のプロダクトから読みたい場合はIcebergを選択する、なければDeltaでOK
まとめ
ここまででDatabricksでのIcebergのはじめ方と現状、考え方みたいな所を書かせていただきました!
まとめると、
- DatabricksでIceberg使うのはめっちゃ簡単!
- Unity Catalogで統合管理できるから、権限管理もリネージもバッチリ
- 他のサービスとの相互運用性が高い!マルチクラウド時代に強い!
- まだいくつか制限はあるけど、基本的な使い方なら全然OK!
- DeltaとIcebergは適材適所で使い分けを!
上にも書きましたが、個人的にはDatabricks内で完結する部分はDelta、他のサービスとの連携が必要ならIcebergって感じで使い分けるのが良いんじゃないかなーと思ってます!
そんなこんなで、シンプルにIcebergを始められる時代になりました、良い時代ですねぇーw
ではでは!




コメントを残す