
仰々しいタイトルw
そんな大きな事言うことはないんですが(おい)僕個人としてもLakebaseがDatabricksの中で何をするものなのかを考えてみたくなりました。
Databricksの公式見解ではありませんが、一つの意見として御覧くださいね!
まずは使ってみよう!
コンピュートの所からデータベースのインスタンスを、、、選んで作成!
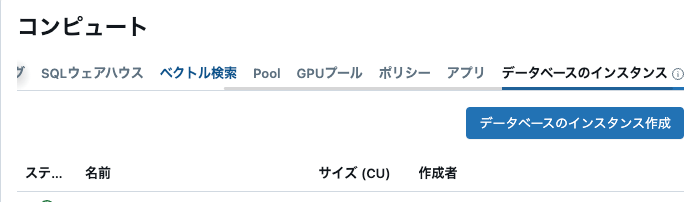
ポチポチですぐデータベースができるんやで。
次はLakebaseをUnity Catalogで管理するように設定!

これでUnity Catalog上で”kuwano_lakebase”という形で見れるようになりますね。同時にkuwano_lakebaseという名前でPostgreSQL上にデータベースが作成されます(既存DBを使うこともできます)
じゃあ接続
OAuthトークンの発行し、


ログイン成功だああああああああああああああああああ!!!
databricks_postgres=> \c kuwano_lakebase
kuwano_lakebase=>
データベースも変更できる!PostgreSQLに慣れてない!w
次はDelta Tableとの同期!
こんな感じで同期テーブルを作成するとDelta Tableの内容をLakebaseへとデータを同期するパイプラインを作成することができます。
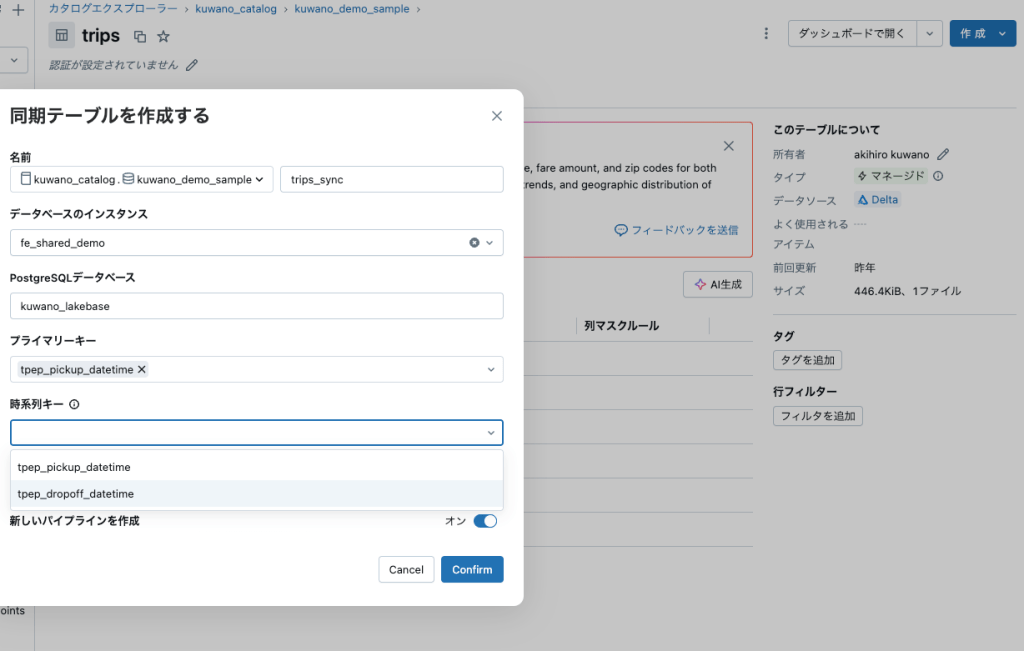
簡単!
データベースブランチ事始め。
ブランチができるっていってましたよねぇ、、、、、?
データベースでブランチが切れるってなに、、、?やってみよ、、、!
まずデータを投入
CREATE TABLE Post (
id INT PRIMARY KEY,
title VARCHAR(255),
content TEXT,
author_name VARCHAR(100),
date_published DATE
);
INSERT INTO Post (id, title, content, author_name, date_published)
VALUES
(1, 'My first post', 'This is the content of the first post.', 'Alice', '2023-01-01'),
(2, 'My second post', 'This is the content of the second post.', 'Alice', '2023-02-01'),
(3, 'Old post by Bob', 'This is an old post by Bob.', 'Bob', '2020-01-01'),
(4, 'Recent post by Bob', 'This is a recent post by Bob.', 'Bob', '2023-06-01'),
(5, 'Another old post', 'This is another old post.', 'Alice', '2019-06-01');
そして子インスタンスの作成
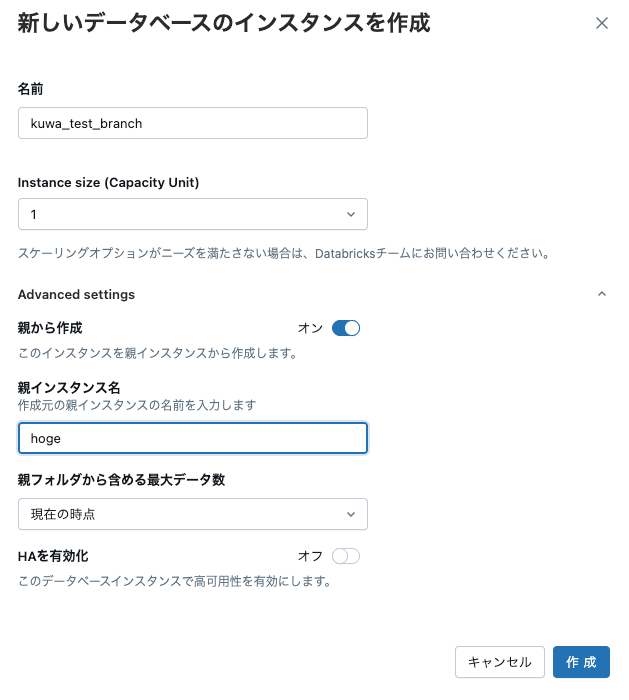
これで瞬時に親インスタンスの現在の時点の情報をもった子インスタンスが作成されるわけです!
こちらの子データベースを使って新規開発やテストを行い、問題なければ本番側に切り替え、といった事が可能になります
きっとこのあたりはNeonさんの技術が入ってもっとDevExを高めてくれると信じてます。
ではLakebaseはなんなのか
そんなLakebaseがDAISで出てきましたが、なぜDatabricksにLakebaseが必要だったのでしょうか。
RDSの置き換え?じゃないですね、LakebaseはRDSのすべての機能を実現できているわけではないからです。制限事項を見てみましょう。
制限事項と要件
ワークスペースでは、最大 10 個のインスタンスを使用できます。
各インスタンスは、最大 1000 の並列接続をサポートします。
インスタンス内のすべてのデータベースの論理サイズ制限は 2 TB です。
データベース インスタンスのスコープは 1 つのワークスペースです。ユーザーは、同じメタストアにアタッチされている他のワークスペースから必要な Unity Catalog アクセス許可を持っている場合、カタログ エクスプローラーでこれらのテーブルを表示できますが、テーブルの内容にはアクセスできません。今後緩和されていくとは思いますが、現状のRDSと比べると限定された用途を想定しているのは明らかだと思います。
機能を並べ直すとこうなります。
- 即座に起動できるOLTPデータベース
- Delta Tableとの同期機能付き
- ブランチ機能の実装
そしてリリースブログの内容も踏まえると、このような使い方が現状のメインになるのではないでしょうか?
- プロダクションレベルのAI Agentを作るのに必要なOLTPのようなレイテンシの低いワークロードにも使えるデータベース
- AI Agentのメモリー機能など
- pgvectorなどを使ったVector Indexとしての利用
- MCPサーバから使用するためのDBとして
- Delta Tableとの同期を活用し、Databricks Appsのデータアプリケーションを低レイテンシでの提供
- リアルタイム推論など、今まではクラウド側に戻さないといけなかったユースケースがDatabricks Appsと組み合わせることで可能なユースケースも増える
- PostGISや、Vector Indexなどでの用途でも使える
- フィーチャーストアのオンラインストアとして使用することでよりレイテンシを気にすることなくML開発を行う
つまり、AI/MLに使うためにはOLAPなデータベースだけでは完璧なユースケースを用意できなかった、そのためそれらのユースケースをカバーするためにOLTPデータベースを用意しました、という話だと理解しました。
段々用途は広がっていくかと思いますが、現状でもすでにこれだけできるようになることにワクワクします!
ぜひLakebase、試してみてくださいませ!





2025年の総括、そしてDATAとAIを追いかけ続けた年の記録(のはず) – 256bitのミステリ世界 への返信 コメントをキャンセル