
勝手に始まったこのシリーズ。ぼくが学んだことを勝手にBlogにしていきます。
Data Vaultsって?
それではData Vaultsについて軽く説明していきましょう!
Data Vaultsの特徴としては、よりアジャイルでスケーラブルなデータ構造を実現できる点です。
ビジネスデータが変化してもすぐに対応できる点が大きく、アジャイルというのはデータの変更に柔軟に対応できるという点になっているわけです。
加えて各レコードに履歴情報を持つため履歴管理にも強いデータモデリング形式です。
Data Valutsのデータモデルとしては、主にハブ、リンク、サテライトの3つのテーブルで構築されます。
- ハブ(Hubs) – 各ハブはビジネスの核となる概念を表す。例えば、顧客ID、商品番号、車両識別番号(VIN)など
- リンク(Links) – ビジネスキー同士の関係性を表現する
- サテライト(Satellites) – サテライトは、核となるビジネス概念に関する説明的な情報を補完する役割を果たします。サテライトはハブに属する情報や、ハブ間の関係性に関する情報を格納します。
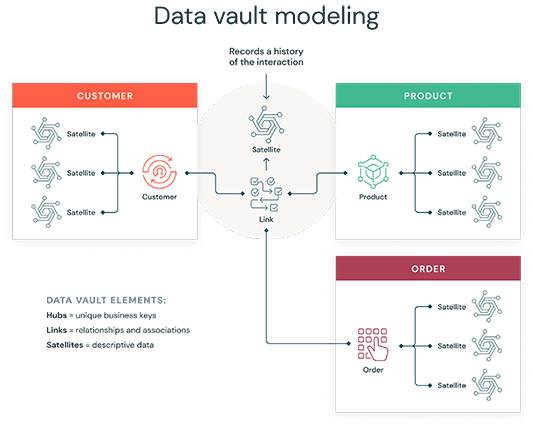
図としてはこの様になります。
ユーザはハブに対してクエリを発行します。
ハブはクエリに関連した属性を含むサテライトテーブルにリンクしている、という関係性となるわけです。
詳しくはここに説明があるのでみてみましょう!
それではサンプルを作って実行しよう
やはりサンプルといえばAI様々、、、LLMでサンプル作って実行してみましょう!
Data Vaultのサンプルデータがほしいです。
* 売上データをテーマにして
* シンプルでわかりやすいサンプル
* サンプルデータそのものも生成してほしいです
* サンプルクエリもほしいです
* Sparkで実行できるものがほしいですこんな感じのプロンプトで生成してもらったコードでできたものを少し手直しして実行してみます!
%sql
-- CATALOGとSCHEMAの作成
CREATE CATALOG IF NOT EXISTS sample_catalog;
USE CATALOG sample_catalog;
CREATE SCHEMA IF NOT EXISTS datavaults_sample;
from pyspark.sql.functions import *
from datetime import datetime, timedelta
import random
# サンプルデータの生成
# 顧客データ
customer_data = [(i, f"Customer_{i}", f"City_{i%5}") for i in range(1, 11)]
customer_df = spark.createDataFrame(customer_data, ["customer_id", "customer_name", "city"])
# 商品データ
product_data = [(i, f"Product_{i}", random.randint(1000, 5000)) for i in range(1, 6)]
product_df = spark.createDataFrame(product_data, ["product_id", "product_name", "price"])
# 売上データ
sales_data = []
start_date = datetime(2024, 1, 1)
for i in range(100):
sales_data.append((
i + 1, # sales_id
random.randint(1, 10), # customer_id
random.randint(1, 5), # product_id
random.randint(1, 5), # quantity
start_date + timedelta(days=random.randint(0, 90)) # transaction_date
))
sales_df = spark.createDataFrame(sales_data,
["sales_id", "customer_id", "product_id", "quantity", "transaction_date"])
# Data Vaults モデルの作成
# Hub Tables
hub_customer = customer_df.select(
sha2(col("customer_id").cast("string"), 256).alias("customer_hk"),
col("customer_id").alias("customer_bk"),
current_timestamp().alias("load_date")
)
hub_product = product_df.select(
sha2(col("product_id").cast("string"), 256).alias("product_hk"),
col("product_id").alias("product_bk"),
current_timestamp().alias("load_date")
)
# Satellite Tables
sat_customer = customer_df.select(
sha2(col("customer_id").cast("string"), 256).alias("customer_hk"),
col("customer_name"),
col("city"),
current_timestamp().alias("load_date"),
lit(True).alias("is_current")
)
sat_product = product_df.select(
sha2(col("product_id").cast("string"), 256).alias("product_hk"),
col("product_name"),
col("price"),
current_timestamp().alias("load_date"),
lit(True).alias("is_current")
)
# Link Table
link_sales = sales_df.select(
sha2(concat(
col("sales_id").cast("string"),
col("customer_id").cast("string"),
col("product_id").cast("string")
), 256).alias("link_sales_hk"),
sha2(col("customer_id").cast("string"), 256).alias("customer_hk"),
sha2(col("product_id").cast("string"), 256).alias("product_hk"),
col("sales_id").alias("sales_bk"),
current_timestamp().alias("load_date")
)
# Satellite for Link
sat_sales = sales_df.select(
sha2(concat(
col("sales_id").cast("string"),
col("customer_id").cast("string"),
col("product_id").cast("string")
), 256).alias("link_sales_hk"),
col("quantity"),
col("transaction_date"),
current_timestamp().alias("load_date"),
lit(True).alias("is_current")
)
# テーブルの書き込み
hub_customer.write.mode("overwrite").saveAsTable("sample_catalog.datavaults_sample.hub_customer")
hub_product.write.mode("overwrite").saveAsTable("sample_catalog.datavaults_sample.hub_product")
sat_customer.write.mode("overwrite").saveAsTable("sample_catalog.datavaults_sample.sat_customer")
sat_product.write.mode("overwrite").saveAsTable("sample_catalog.datavaults_sample.sat_product")
link_sales.write.mode("overwrite").saveAsTable("sample_catalog.datavaults_sample.link_sales")
sat_sales.write.mode("overwrite").saveAsTable("sample_catalog.datavaults_sample.sat_sales")
これを実行すると簡単なData Vaults形式のテーブルが生成されます。
カタログに行ってみてみましょう。
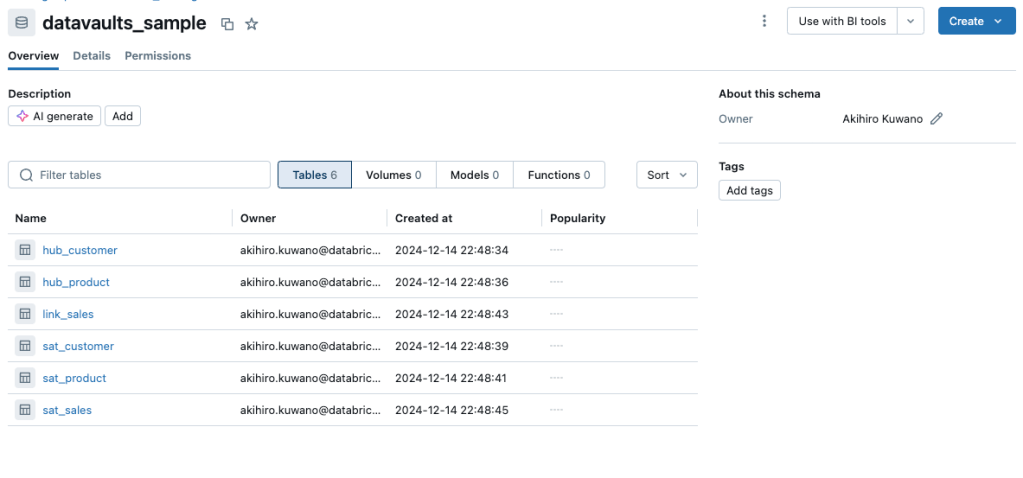
次はこのデータにアクセスするためのクエリ例です。
%sql
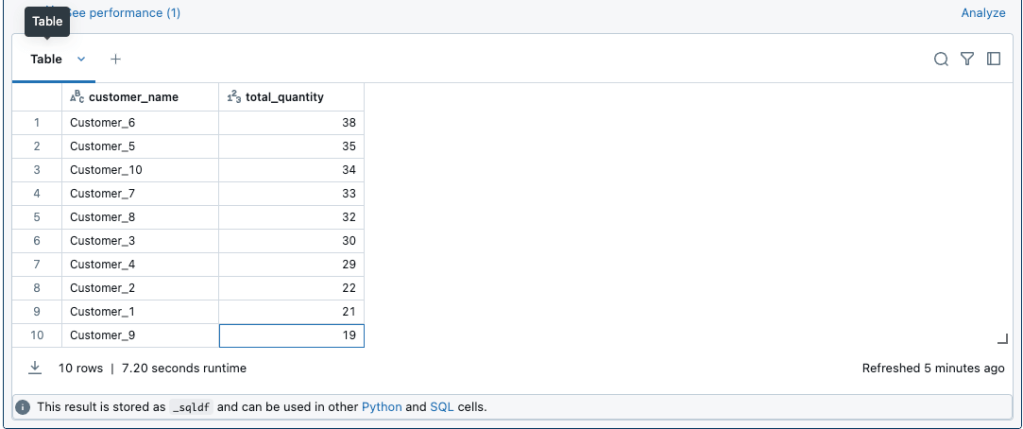
-- 1. 顧客ごとの総売上数量を取得
SELECT
sc.customer_name,
SUM(ss.quantity) as total_quantity
FROM sample_catalog.datavaults_sample.link_sales ls
JOIN sample_catalog.datavaults_sample.hub_customer hc ON ls.customer_hk = hc.customer_hk
JOIN sample_catalog.datavaults_sample.sat_customer sc ON hc.customer_hk = sc.customer_hk
JOIN sample_catalog.datavaults_sample.sat_sales ss ON ls.link_sales_hk = ss.link_sales_hk
WHERE sc.is_current = true
GROUP BY sc.customer_name
ORDER BY total_quantity DESC;
%sql
-- 2. 商品ごとの売上金額を計算
SELECT
sp.product_name,
sp.price,
SUM(ss.quantity) as total_quantity,
sp.price * SUM(ss.quantity) as total_amount
FROM sample_catalog.datavaults_sample.link_sales ls
JOIN sample_catalog.datavaults_sample.hub_product hp ON ls.product_hk = hp.product_hk
JOIN sample_catalog.datavaults_sample.sat_product sp ON hp.product_hk = sp.product_hk
JOIN sample_catalog.datavaults_sample.sat_sales ss ON ls.link_sales_hk = ss.link_sales_hk
WHERE sp.is_current = true
GROUP BY sp.product_name, sp.price
ORDER BY total_amount DESC;

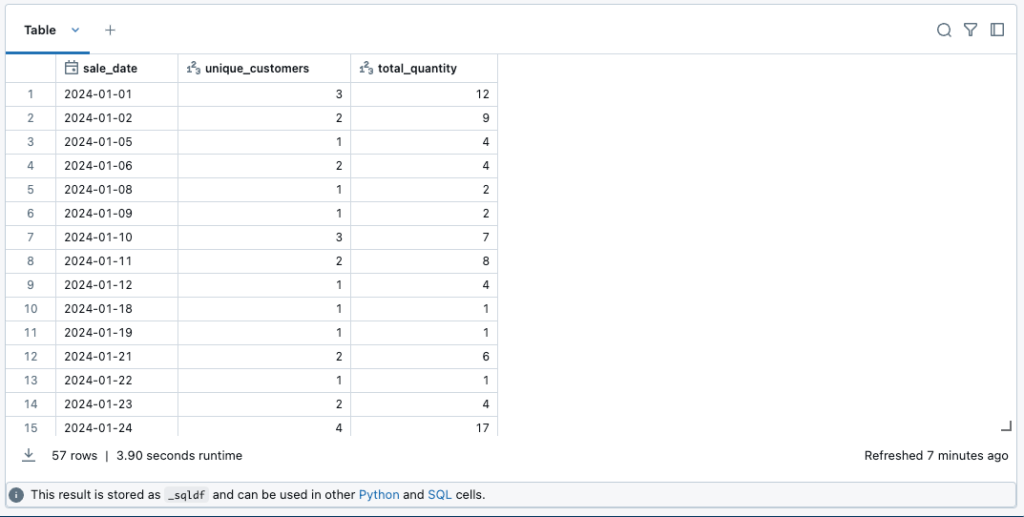
%sql
-- 3. 日付別の売上集計
SELECT
DATE(ss.transaction_date) as sale_date,
COUNT(DISTINCT ls.customer_hk) as unique_customers,
SUM(ss.quantity) as total_quantity
FROM sample_catalog.datavaults_sample.link_sales ls
JOIN sample_catalog.datavaults_sample.sat_sales ss ON ls.link_sales_hk = ss.link_sales_hk
WHERE ss.is_current = true
GROUP BY DATE(ss.transaction_date)
ORDER BY sale_date;
%sql
-- 4. 都市別の売上分析
SELECT
sc.city,
COUNT(DISTINCT ls.customer_hk) as customer_count,
SUM(ss.quantity) as total_quantity,
SUM(ss.quantity * sp.price) as total_amount
FROM sample_catalog.datavaults_sample.link_sales ls
JOIN sample_catalog.datavaults_sample.hub_customer hc ON ls.customer_hk = hc.customer_hk
JOIN sample_catalog.datavaults_sample.sat_customer sc ON hc.customer_hk = sc.customer_hk
JOIN sample_catalog.datavaults_sample.hub_product hp ON ls.product_hk = hp.product_hk
JOIN sample_catalog.datavaults_sample.sat_product sp ON hp.product_hk = sp.product_hk
JOIN sample_catalog.datavaults_sample.sat_sales ss ON ls.link_sales_hk = ss.link_sales_hk
WHERE sc.is_current = true
AND sp.is_current = true
GROUP BY sc.city
ORDER BY total_amount DESC;
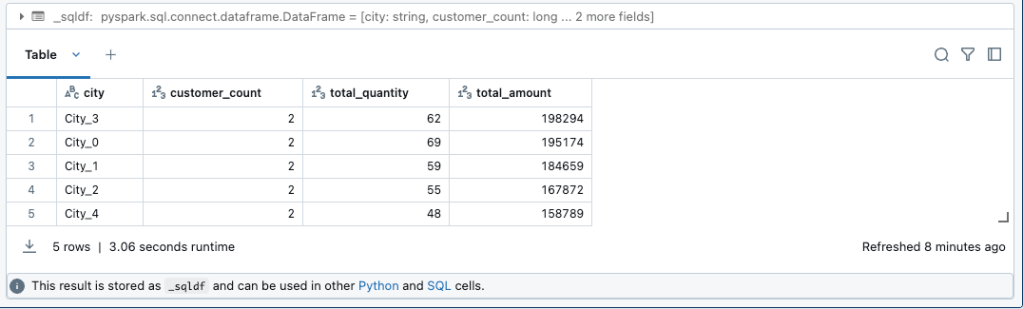
ちゃんとデータは取れてそうです!
やってみると解像度があがりますが、なにか変更などがあってもサテライトの変更だけでいけるというのは確かに変化に強そうなデータモデリング手法だなという印象でした。
すぐ試せたよ
Data Vaultsのデータモデリングの勉強をするのにDatabricksとLLMを使ってすぐに試すことができました。
自分の知識の底上げにAIを使っていくのは便利だなぁという印象です。もう少し自分でもデータパイプラインにいれてみてどうなるかなども試してみようと思います。
ではでは!




コメントを残す