
いや、もうタイトルは迷子だよ。
こんにちは!みなさんお元気ですか!
職業柄Databricksによく触るわけなんですけど(そらそうだ)正直、メチャクチャDatabricks好きなわけです、良いと思ったのでDatabricksに入ったわけだし。
だけどまだまだDatabricksについて知らない方もたくさんいらっしゃるんですよね、なので今日はDatabricksって何がいいのか、とかそれは誤解かもしれないなぁ、とかそういうのを徒然なるままに書いていくよ!
何がいいんだろうね?
まずいいところを思いつく所から書いていきたいと思いますね!
- まずは何を言ってもデータレイクハウスによるクラウドストレージを使いつつトランザクションや、バージョン管理を行えるアーキテクチャを最初からとっている点。
- そして、スモールスタートからビッグテックまで使える土壌がある点。
- Unity Catalogのメタストアによるカタログや、モデル管理、権限管理などの統合管理などなど。
- ワンストップでデータ活用からAI/MLまで使える広いユースケースのカバーしている点。
- そして、分散コンピューティングによる高いスケーラビリティ。
これらを持つ基盤がDatabricksなわけです、良さそうに見えますよね、、、これが実際に良いんですよ!(何
特にこれって言う所を書いていこうと思います。
もちろんこれでしょデータレイクハウス
まずはデータレイクハウスですね。データウェアハウスの様に大量のデータを腹持ちするのではなく、クラウドストレージにもち、さらにトランザクションログを持つオープンテーブルフォーマット(DatabricksだとDelta Lake)でもち、クラウドストレージをDWH的に使うアーキテクチャです。コンピュートとストレージを分離し、各リソースを効率よく使うことができます。
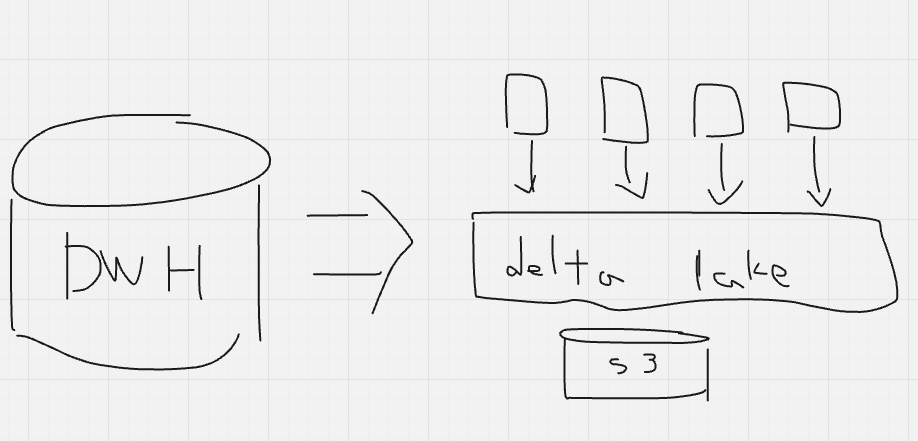
このアーキテクチャがめちゃいい、、、わけです。クラウドストレージって広義で言うとキーバリューストアなので普通に使うと上書きできないし、RESTful APIでアクセスするのでオーバーヘッドもかかります。そこをOTFが吸収してくれると言う訳です、パーテショニングなどのデータ分散や、キャッシュなどを活用したクラウドストレージの性能の最適化もしています。
詳しくはデータレイクハウスについてはここ、Delta Lakeについてはここを見ていただけるとより詳しい説明があるので良いです!
スモールスタートからビッグテックまで
前こんな事をかいたんです
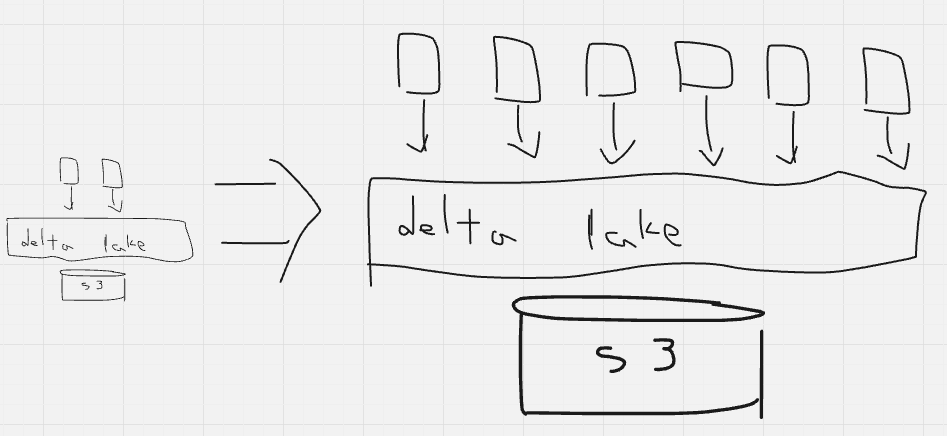
ここに大体言いたいことは書いたんですが、データレイクハウスという構成を組めることによって、ストレージはS3などのクラウドストレージの従量課金、そしてコンピュートも利用実績に応じたクラスタ群を立てるだけとなります。更に最近出た各種サーバレスを活用することでクラスタも更に使用時のみの従量課金とすることが可能になるわけです。
これにより実現できるのは[ 性能 & コスト]を最適化した高コストパフォーマンスかつ成長に対応できる実行環境です。
要するに、最初から大きい箱みたいな物を用意することなく、必要なリソースを必要なだけ持つことができるようになる。加えてその規模感が大きくなったときにも単純に規模感が大きくなるだけで大きな構成変更を行う必要が無い、少ない、という所が良い部分だと思います。
とても大事なUnity Catalog
Unity CatalogはDatabricksを代表とするサービスになったと思います。
データカタログや、データリネージ(世代管理)、それだけではなく機械学習のモデル管理や、各種権限管理、ボリュームの提供、マネージドテーブルの提供などなど。
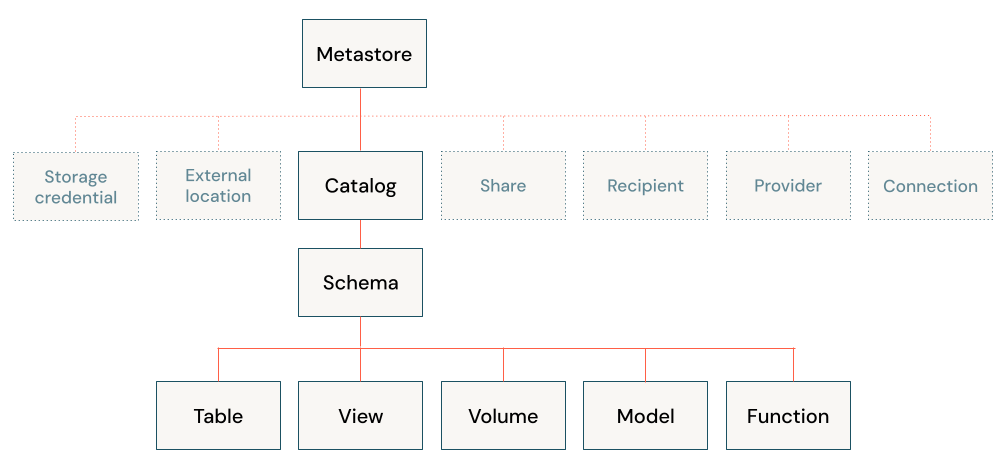
こんな感じでメチャクチャあるわけです。
しかも複数のワークスペースを束ねて管理できますし1つのワークスペースを細かく管理することもできるため、データメッシュにも中央集権にも対応できる柔軟性があります。
最初は中央集権で初めて、大きな組織を分割するタイミングになったらワークスペースを切り出していきデータメッシュに切り替えていくということも可能です。
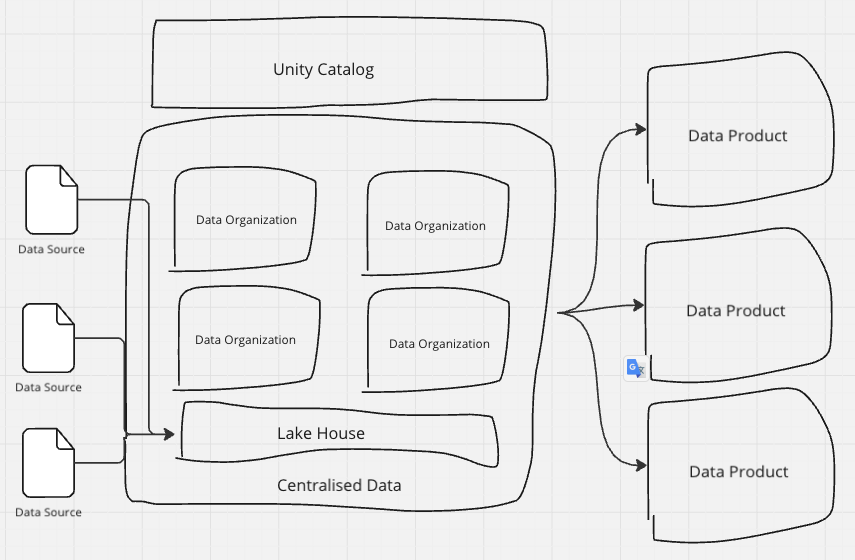
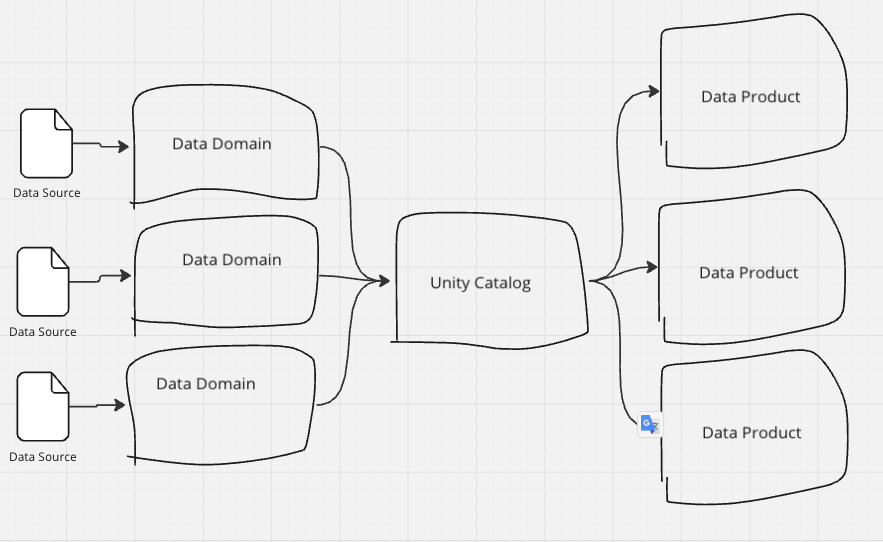
このように各ドメインを統合して管理できるUnity Catalogのお陰でこれが実現できるわけです。
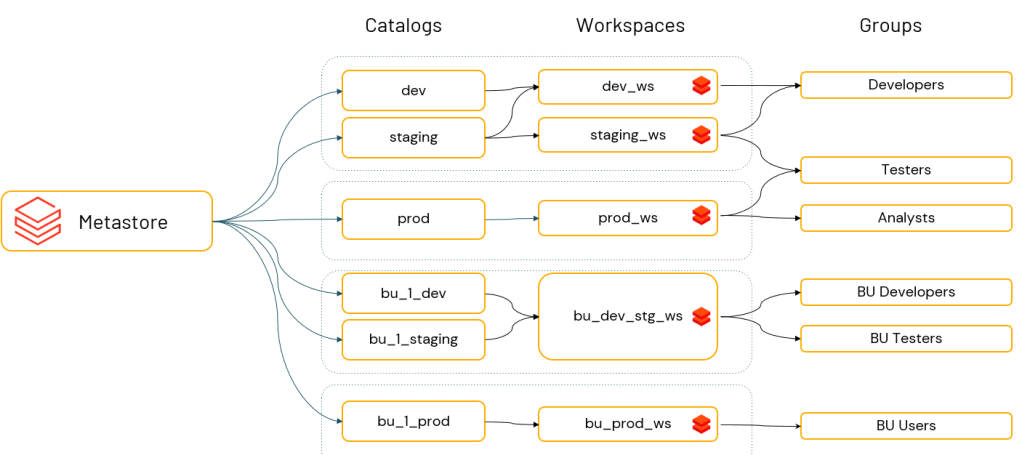
ただのデータカタログではなく、メタストアとして様々なメタデータを保存し、提供するUnity CatalogがDatabricksの一つの強みだと思っています!
最近OSS化しましたが、まだVersion 0.1なのでこれから機能拡充していくとUnity Catalogエコシステムが成長していって面白いことになる気がします!
オールインワンなプロダクト
オールインワン!🐶
たとえばデータを取り込む、データを加工する、まずはノートブックで加工してみて、できたらそれをワークフローとして実行しよう、データをサーブして、データをBIツールで見よう、データを機械学習で使おう、機械学習の推論エンドポイントを作ろう、LLMをサービングしよう、ベクターサーチにデータ入れてRAGをしよう、ファインチューニングをAPIでしよう、プリトレーニングをしよう、、、データを使ってやりたいことは色々あります。
Databricksはそれらの機能を全て持っています、すでに統合された機能として持っているわけです、組み合わせる負荷を最小限に様々な機能を使用可能というわけです。
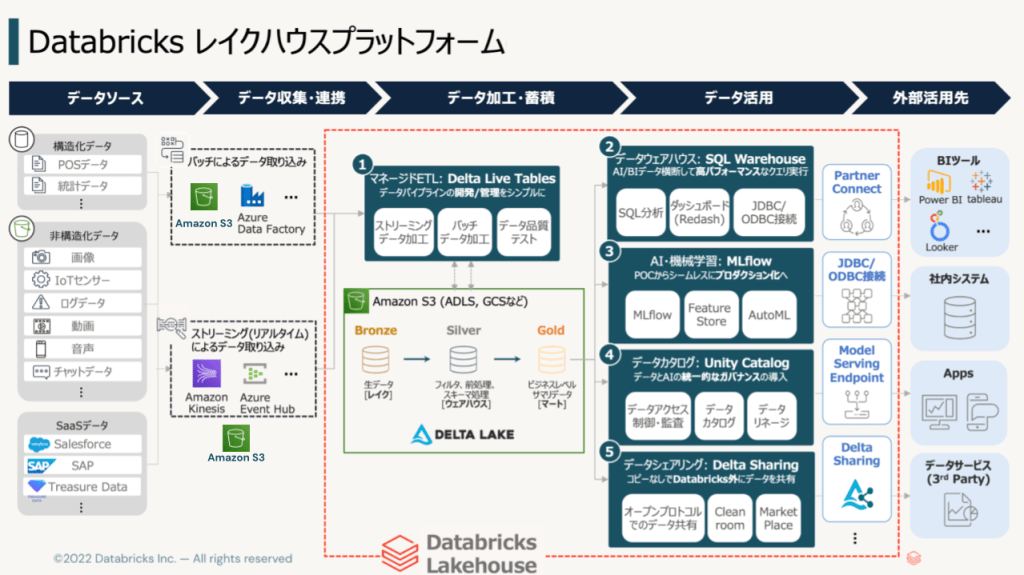
そしてこれからもそれらの機能がドンドン追加されていくと思います。
最近でいうとLakeflowシリーズが発表されましたが、Ingest、Transform、Orchestrateをより統合したものになる予定です
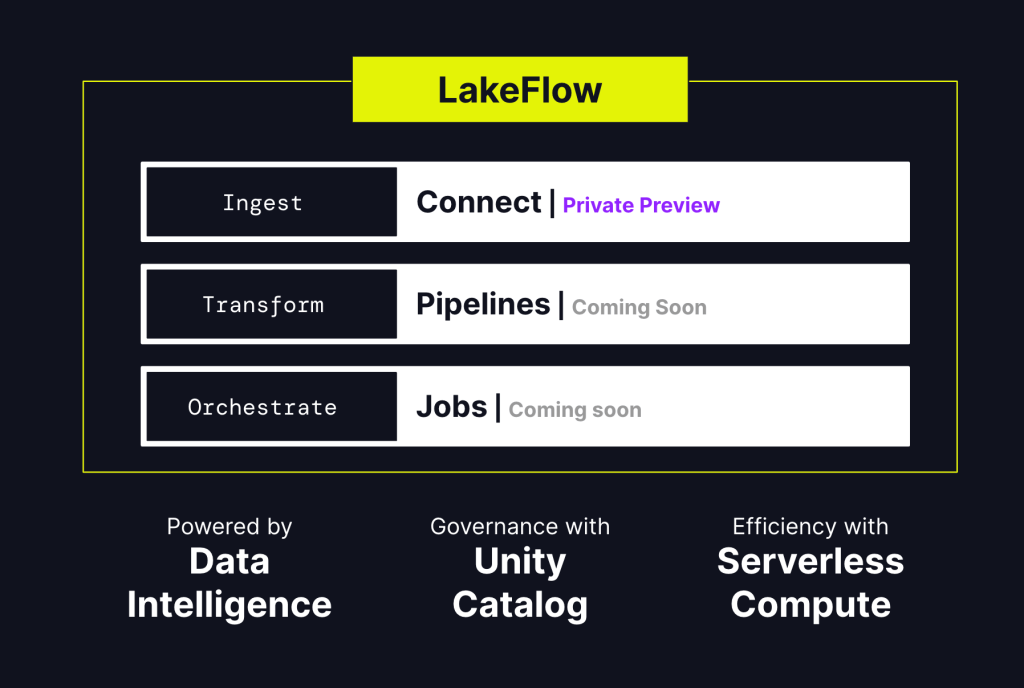
もちろん組み合わせたい場合もあると思います、その場合は組み合わせられる柔軟性も持っています!
Sparkを使いたいからDatabricks?
これ!結構いわれるんですよね!「Databricks使うのにSpark知らないといけないんでしょ」とか「SparkとかHiveとか使ってると入りやすいけどそうじゃないと厳しいんでしょ?」みたいなお話です。
これは現在ではそんな事も無いと思っていて、Sparkはもちろん現在でもDatabricksの根底となる技術ではあります。ですが、深く知る必要は必ずしもなく、マネージドの形で提供しているためある程度Sparkそのものについて知らずとも使えるようになっています。
更にDBSQLという形でSQLだけでも操作できるようになってきたり、DWHとしてのDatabricksも存在感だしてきています。
こんな本もありますよ(宣伝!w)
PySparkはあるともちろん便利です。
確かにPySparkは通常のPythonと比べるとちょっとクセがあるのですが、慣れるとシンプルな構文の繰り返しなので慣れの問題だと思ってるんですけどいかがでしょうか😅
Spark Connectみたいな、SparkをAPIで動かそうといったプロジェクトも進んできていてそのうち色々なアプリケーションや、Go言語などの他の言語からSparkがさわれる日も近いんじゃないかなと思ってます。
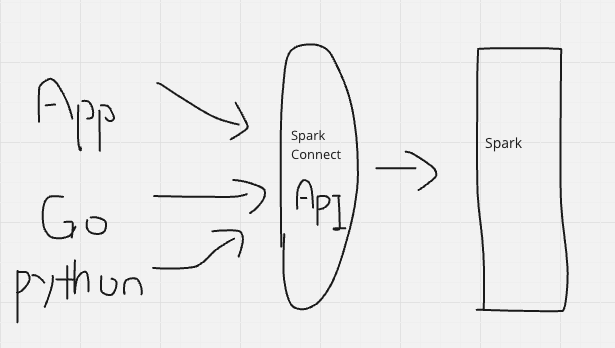
とはいえSparkを知ったほうがよりDatabricksを知ることができるのは間違いなくて、感覚としては、「Sparkを深く知らなくてもDatabricksは全然問題ない。でもSparkを深く知るとよりうまく使える。」が近いのかなぁと思ってます。(深く知りたい)
まとめ
ここまでDatabricksの何がいいのか、なんで使うのか、についてお話していきました。ここまで読んでいただいた方で「ガッテンDatabricks」と思っていただいた方は是非お声がけいただければと思います!
定期的にSAがオフィスアワー的なものもやってますよ!
そんなこんなで新しいデータ分析クラス3-B組の仲間になったDatabricksさんの明日はどっちだ!!!
(締め方がわからなくなったので勢いで終わろうと思います)





Databricks情報を手に入れろ!?Databricks関連書籍やウェブ上のポインタなど(長い) – 256bitのミステリ世界 への返信 コメントをキャンセル