
どうも、くわのです。
前回はほぼDatabricksカスらせただけに終わったのでとても申し訳なく思っています。今回はDatabricks Advent Calenderの15日の記事です!
marimoってなんだろうって思って調べてみた
って、調べてみた記事書こうとしてたんすよ!
でも、、、出ちゃうじゃん、いい記事でちゃうじゃん!
「もうJupyterに戻れない。次世代Notebook“marimo”を使ったら革命だった」
記事を読みました、良い入門記事になっていました、、、!

なんでmarimoそのものが何かについてはこちらの記事を見ましょう!w
というわけで、、、じゃあどうする、、、?
色々考えた結果、これにすることにしました「Databricks NotebookとMarimoはどう使い分ける?」

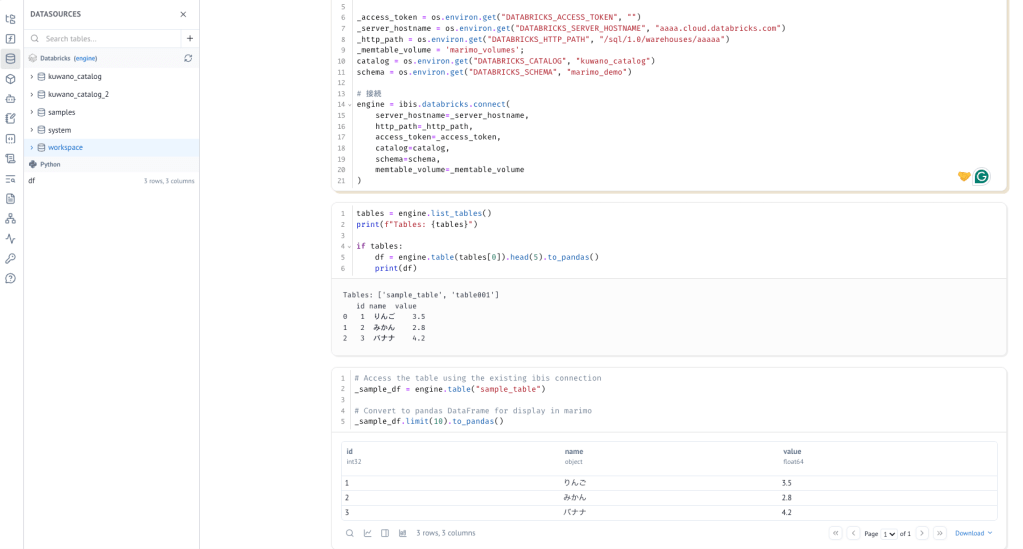
手前味噌ながらDatabricks Notebookはかなりいい感じだと思っています。それとmarimoはどう使い分けるべきなのか、コレを考えてみようと思います。
marimoのメリットを考える
先の記事にも書いてありますが、marimoにはこのようなメリットがあります。
- リアクティブ実行と隠れ状態の排除による再現性
- セルをDAGとして扱い、依存関係に基づいて自動再実行・状態リセットを行う
- そのため「実行順のせいで動いた/動かない」といったノートブック特有のバグを避けやすい
- ノートがそのまま純粋なPythonファイルである
- これはそのままPythonファイルとして実行できるし、Notebookの弱点だった、Git対応しづらいに見事に対応している一つの形だと思います
- コード上でマルチデータソース(DBとか)の対応がしやすい
- 複数プロダクトの環境を取ってきてJOINとかをしやすい(最近はibisとか便利そうなものもあるようです)
- これはメリットでもデメリットでもあると思います(ゴチャゴチャになりやすそう
marimoのデメリットを考える
いい部分もあれば悪い部分もあるように思いました
- リアクティブ実行の今までのノートブックとの使用感の違い
- セルに分割されていた今までの使用感からセル間のつながりの強いリアクティブ実行は作業していて若干慣れないです
- 長時間バッチや巨大ジョブにはやや不向き
- 特にDatabricksだと大量のデータをibisでpandas dfで処理させるのは考えるだけでも厳しくなりそう
- 1ノートブックが1Pythonコードになるが、Pythonコードとしては素直なコードではない(それでもNotebookよりは見やすいけど)
- リアクティブ実行の部分とちょっと被りますがimport管理や、変数管理なども結構セル間の依存がきびしくてちょっとそこも直感的じゃないなーとか思いました
- Databricks Notebookのように複数人の同時実行を前提としていない
- 結構自分的にはDatabricks Notebookでのペアプロ、モブプロ的なの好きだったりするのでこれができないのは個人的には寂しいです(寂しさとは?)
じゃあ、、、どうする?
ここからどう使い分けるかを考えます。思考ダダ漏れで書くので諦めて読んでくださいw
アドホック分析についてはどうでしょう?
アドホック分析を行うにはpandasで処理してもそこまで大きくならない?事も多そうです。Databricks Notebookも使えますが、marimoも良さそう。
ローカルでのsklearnの試行とかにもローカルで動かして、リモートのDatabricksのMLflowに実験管理を飛ばせば今までみなさん気になっていたDSのローカル開発環境についてはある程度良くなるパターンがありそうです。逆に大規模なML環境ということであれば素直にDatabricks側でやるほうが良い気がしますね。
データの品質チェックなど結果の検証などもそこまで重い処理にならない気がしますが、DatabricksにもLakeflow monitoringなど色々機能があるので、オーバーラップしそうな気はしますね、考えるところは多そう。
シンプルに複数データをまたぐようなアホドックな分析には使える部分がありそう。例えばDatabricksとBigQuery、Snowflakeとか、S3バックエンドなDuckDBとのibis使ってJoinするとか。Databricksもremote-queryとかでたからその辺使い分けもあると思うけどね。
ETL処理についてはDatabricks側でやるほうが良いと思います。データ量も多いですし、途中で正しく動いているかを確認する必要もありそうですし、恐らくそれらを見ていくと重くなりそうなのでストレスたまりそうです。Spark Declarative Pipelineとかもありますし。
実験とかPoC用のアプリ作成の試作にもmarimoが使えるかも知れない。
marimoはPythonのみなので、マルチリンガル的な部分であればDatabricks Notebookは良いです、セル間連携も気持ちがいいです。
Agentic CodingとかはNotebookでもある程度追従してくれるようになってきてはいるのでそこまでかわらないのかもなー、marimoもちょっと特殊なコードだしなーって気持ちです。(やってみな
というわけで、、、。
今までを踏まえたうえでこんな感じになるのかなぁというのをまとめました。
Databricks側としては、ETLの実行やスケジューリング、監視といった「性能が必要で繰り返し動く処理」はDatabricks側に集約し、それらの処理の後で人間がデータに触れて考えたり説明したりする部分をmarimoに任せる、という役割分担はしっくり来るのかなぁ、と。
Databricksはクラスター管理やDelta Lake、Lakeflowといった機能で、毎日・毎時間のETLパイプラインを安定して動かし続けられるのはとてもいい部分で、一方marimoはそのETLが作ってくれたゴールドテーブルを読み込んで、スライダーなどで条件を変えながら分布を見たり、品質指標を確認したり、可視化付きのまさにノートブックとしてまとめるなどの使い方が便利そうです。
ETLの後で、実際に流れてきたデータをmarimoで対話的に確認し、ドリルダウンして、ビジネス側の人と話し合うとか、そういうのはmarimoもやりやすそう。
要するに、Databricksは「大量データを安定的にさばく基盤」として使うことができ、marimoは「データの意味などを人が理解し、共有する所」みたいに使う感じでどちらもうまく活用することができるかもなーとおもいました。もちろんDatabricks Notebookではできないとかじゃないんですけどね!w
ただ、marimoも0.18.4でまだまだな部分もあるように思うので、引き続き触っていって、チョコチョコフィードバックしていこうと思いました。ibisも便利そうだけど壮大で大変そうな雰囲気がありますね。
結論こんな感じになるのかなーと思いました。
そんな感じです!まりも!(名前がかわいい)





コメントを残す