
こんちゃ、たまーに流れてくるスキーマレスの誤解みたいなのがすごい気になるマンです。もう何も関係ないのですがw
い、一応Databricks Advent Calenderの11日の記事なんですけど、書いてるうちにほぼ関係なくなってきたので、、、ごめんw
スキーマレス=スキーマ設計不要?
一応、、、MongoDBに限らずなんですがw
例えばドキュメントストアを使う場合に、あるいはVariant型みたいな自由に突っ込める型の場合に、「スキーマレスだからスキーマの事考えなくて楽だよネ!(*´σー`)エヘヘ」みたいなのは、、、過去の過ちになりますYO!
もちろん実際に運用した時に出てくるわけです、「綺麗に型したいよなぁ」とか「アプリで全部やるんでしたっけ、めんどくないですか?僕はめんどいです!」みたいなことがありますよね。
スキーマレスという言葉は誤解を生み続けている。
スキーマレスだからスキーマの事を考えんくてええんや、みたいなことはないのだ。
スキーマは必ず必要、管理する場所が違うだけ!
スキーマいるんすよ、結局。ごめん。
ここで大事なのは、スキーマレスなデータベース、もしくはそういうJSON突っ込めますよな型って「スキーマが不要」なわけじゃないってことなんですよ。
まあ例えばRDBならこう書くわけです。
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(255) UNIQUE,
status VARCHAR(20)
);
データベース側がスキーマで厳格になっている。制約もある。
でもドキュメントストアだと、データベースにはスキーマを強制しないという話があります(これも令和の今では嘘ですが、それは後で書きます)
同じデータセット内に全く違う構造のドキュメントが入ってても怒られないわけです。
// こんな構造もOK
{"name": "田中", "email": "tanaka@example.com", "status": "active"}
// そして、こんな構造もOK
{"name": "佐藤", "phone": "090-1234-5678", "age": 30, "tags": ["premium"]}
はい!これで自由!ってならんわけですよ、結局。
だって、アプリケーションは、もしくはそれを扱うデータ分析はそれを知ってないといけないわけなので。
要するにこれだけだと、スキーマの管理場所がデータベースからアプリケーションに移っただけなわけです。
逆にめんどくさくない?
じゃあ実際どうしよか?
ではどうするかって言うと、スキーマレスデータベースでのスキーマ管理って、RDBとは考え方を変えないといけないわけです。
フィールド単位での役割を定義する
昔の資料引っ張り出してきましたが、、、w
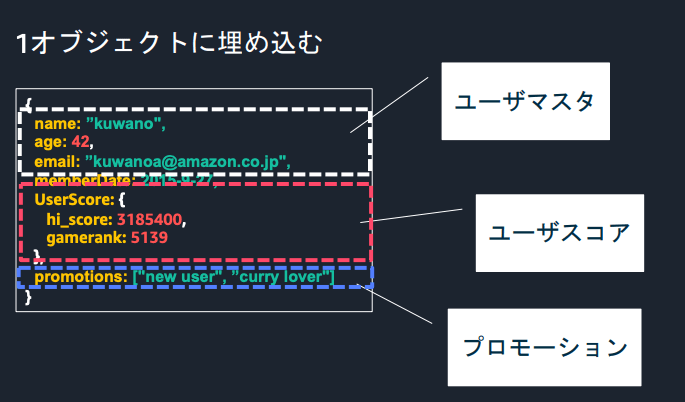
よく言われているのが、RDBだとテーブル設計で厳格にカラムを定義していきますが、スキーマレスDBの場合はもうちょっと大きな粒度で考えるのが良いという話です。
例えば、ユーザー情報を管理するドキュメントがあったとしてここで大事なのは「このフィールドはユーザマスタが入る」「このフィールドはユーザスコアが入る」みたいに、フィールドの役割や責務を定義することです。
細かいカラム単位で「このカラムはVARCHAR(100)で必須」みたいに決めるんじゃなくて、「statusフィールドにはアカウントの状態に関する情報が入る」くらいの粒度で境界を決めていくわけです。
で、それをアプリケーションでバリデーションする。
よさそうですかね?
令和の世の中にはスキーマを厳格にする仕組みもあるんだよ
実は令和のドキュメントデータベースにはスキーマを厳格にする仕組みもあります。
ここまで「アプリケーション層で管理しましょう」って話をしてきましたけど、実はMongoDBみたいなスキーマレスDBにも、スキーマを厳格にする仕組みがちゃんと備わっています。
MongoDB Schema Validation
MongoDBにはSchema Validationという機能があって、これを使うとデータベース層でスキーマを強制できます。
db.createCollection("users", {
validator: {
$jsonSchema: {
bsonType: "object",
required: ["userId", "profile", "status"],
properties: {
userId: {
bsonType: "string"
},
profile: {
bsonType: "object",
required: ["name", "email"],
properties: {
name: { bsonType: "string" },
email: {
bsonType: "string",
pattern: "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$"
}
}
},
status: {
bsonType: "object",
required: ["accountStatus"],
properties: {
accountStatus: {
enum: ["active", "inactive", "suspended"]
}
}
}
}
}
}
})
こうすると、スキーマに合わないドキュメントを挿入しようとするとエラーになります。めっちゃRDBっぽいですよね。
ODM側での定義
あとは最近はBeanieみたいなODM(Object Document Mapper)を使う方法もあります。(つーか実際の定義部分はPydanticですね)
from beanie import Document
from pydantic import Field
from typing import Literal
from datetime import datetime
class UserStatus(BaseModel):
account_status: Literal['active', 'inactive', 'suspended']
last_login: datetime | None = None
login_count: int = 0
class UserProfile(BaseModel):
name: str
email: str
class User(Document):
user_id: str = Field(unique=True)
profile: UserProfile
status: UserStatus
class Settings:
name = "users"
こうすることで、アプリケーション層でもデータベース層でも、スキーマを強制できてしまう。
要するに、もはや必要に応じて厳格にもできるし、柔軟にもできる、それがスキーマレスDBの強みとなるわけです。
閑話休題(あるいはこれでDatabricksに関係あると言い張りたい俺)
じゃあDatabricksでは関係ないのかというと、Variant型っていうのがありまして、これもスキーマバリデーションしたかったら、Pydanticとかでやるのがいいですね!
# こんなデータが入ってるとして
# INSERT INTO demo_variant VALUES
# (1, "kuwano", PARSE_JSON('{"hobby": "Tennis", "sex": 1}')),
# (2, "ito", PARSE_JSON('{"hobby": "Pokemon", "sex": 2}')),
# (3, "shiga", PARSE_JSON('[1, 2, 3]')),
# (4, "ejiri", PARSE_JSON('"hello"'));
from pydantic import BaseModel, ValidationError
import json
from pyspark.sql import Row
# スキーマ定義(例: name: str, age: int)
class DataProperties(BaseModel):
hobby: str
sex: int
class Person(BaseModel):
id: int
name: str
data: Any
@model_validator(mode='after')
def validate_data(self):
# dataがSparkのVariantVal型なら文字列化してjson.loads
if not isinstance(self.data, dict):
try:
self.data = json.loads(str(self.data))
except Exception as e:
raise ValidationError(f"dataフィールドの変換失敗: {e}")
# DataPropertiesでバリデーション
DataProperties(**self.data)
return self
# データ抽出
rows = spark.sql("SELECT id, name, data FROM workspace.default.demo_variant").collect()
for row in rows:
try:
person = Person.model_validate(row.asDict())
print(f"id={person.id} name={person.name} OK: {person.data}")
except ValidationError as e:
print(f"id={row['id']} name={row['name']} NG: {e}")
except Exception as e:
print(f"id={row['id']} name={row['name']} NG: {e}")
とかすると、こんな感じでチェックできます。
id=1 name=kuwano OK: {'hobby': 'Tennis', 'sex': 1}
id=2 name=ito OK: {'hobby': 'Pokemon', 'sex': 2}
id=3 name=shiga NG: __main__.DataProperties() argument after ** must be a mapping, not list
id=4 name=ejiri NG: __main__.DataProperties() argument after ** must be a mapping, not str
もしくはこの前紹介した、DQXなんかもその解決になるかも知れません。
よし、、、Databricks絡めた、、、(達成感)
じゃあ、、、RDBでいいじゃん?
わかってますよ!言いたいことはw
「スキーマちゃんと管理するならRDBでいいじゃん」っていうんでしょ!?そうだよ!!
だから例えばMongoDBみたいなドキュメントDBを使うのであれば他のメリットを見出さないといけないと思ってます。
スキーマ進化の柔軟性
RDBMSの場合はゼロイチです。Alterするにしても、それがゼロダウンタイムでできたとしてもゼロイチになるわけです。
ドキュメントDBであればきれいな形で共存することができます。
スキーマバージョニングパターンと組み合わされる事で、古いドキュメントと、新しいドキュメントを混在させることができます。さらにドキュメントにバージョン番号を入れておくことで古いバージョンで読み込んで、新しいバージョンで書き出す、みたいなこともできるわけです(公式ドキュメントではここ)
サービスを止めずに、段階的にスキーマを進化させていける。これは運用の現場だとかなり重要な要素だと思います。
開発初期の素早いイテレーション
これは特にスタートアップとか新規プロジェクトで重要だと思うんですけど、開発初期って仕様がコロコロ変わるじゃないですか。
「やっぱりこのフィールド必要ないわ」 「この情報も持たせたい」 「このデータ構造、ネストさせたい」
RDBだと、こういう変更のたびにマイグレーションスクリプト書いて、テストして、、、ってなります。
MongoDBなら、アプリケーション側のコード変えるだけで済むことも多いです。もちろん既存データのマイグレーションは考えないといけないですし、上に書いたみたいにある程度のところまでいったらバリデーションも考えないといけないですが。
スピード重視のフェーズでは、この柔軟性はめちゃくちゃ助かるはずで、やはり最初のステージでのドキュメントDBの良さ、というのはあると思います。
水平スケーリングの容易さ
まあこれはMongoDB的な物の話の前提ではありますが、スケーリングが楽なのは間違いないです。
sh.shardCollection("mydb.users", { userId: 1 })
もちろん、シャーディングキーの設計は重要だし、考えることはあります。でもRDBでやるよりずっとシンプルです。
大規模になったときのスケーラビリティを考えると、これは大きなアドバンテージだと思います。
これは思いますが、考える所が違うんですよね、スケールは楽だけど、アプリケーションで考える所は多くなる、だからそれを考えないといけなかった、そうじゃないと負債が溜まるよ。と。
「ドキュメントデータベースだから失敗した」ではない
ここまで色々書いてきましたけど、結局何が言いたいかというと、
例えば、「MongoDBみたいなスキーマレスDBを使ったから失敗した」じゃなくて「スキーマ設計・運用を失敗しただけ」
ってことです。
「MongoDBで運用してたけど運用が大変で結局RDBに戻した」みたいな話よく聞きます。
ただそれは技術選定の問題だけではなくて、設計と運用ルールの問題なんです。スキーマレス=無秩序で良いという勘違いと、運用を回すための継続的な改善ができてなかったってことなんじゃないかと思ったわけです。
MongoDBだろうがDynamoDBだろうが、適切なスキーマ設計と運用ルールがあれば使えるはずで、上に書いたようにそのための部品も増えてます。逆に、RDBだって設計がめちゃくちゃだったら破綻します。
破綻しなければメリットだけを享受できます。
大事なのはそれぞれのデータベースの特性を理解して、適材適所で使うことだと思います。
まとめ
そんなこんなで、令和の今スキーマレスなデータベースについて思うところを書いてみました。
スキーマレスDBを使うなら、その特性を理解して、適切な設計と運用をしていく必要があるってことです。そして何より、「どのデータベースを使うか」よりも、「なぜこの仕様になっていて、このデータベースが必要なのか」の方が先だと思います。思考停止せず、それぞれの良さを活かしていきましょう!
ではでは!スキーマレスレス!(ニュートロンジャマーキャンセラーっぽい)





コメントを残す